FLUX that Plays Music리뷰
by DINHO
오늘은 Fei, Zhengcong, et al. “Flux that plays music.”(2024) 논문 리뷰를 해보겠습니다. 바로 시작해보겠습니다.
Introduction
Text-to-Music은 주로 언어 모델 또는 확산(Diffusion) 모델을 활용합니다. 대표적으로 MusicLM, MusicGen, AudioLDM 등이 있습니다. (첨언: 여기서 이야기 하는 언어모델은 Transformer입니다!! Transformer는 언어모델에서 출발했지만 여러 분야에 사용됩니다.)
확산 모델은 고차원 데이터를 효과적으로 모델링하여 음악 생성에 강력한 성능을 발휘하지만, 계산 비용이 크고 샘플링 시간이 오래 걸립니다. 그래서 FLUX는 Rectified Flow 를 도입합니다.
Rectified Flow는 데이터와 노이즈 간 선형 경로를 정의하여 학습 효율성과 생성 성능을 향상시킵니다. 이 논문에서는 기존 Text-to-Image 오픈소스 모델인 Flux에서 사용한 방법을 음악 생성에도 적용하는 연구를 했습니다.
논문 소개에 따르면 Rectified Flow 기반 Diffusion Transformer를 Text-to-Music에 최초로 적용했다는 점을 이야기하고 있습니다. 이로써 기존 확산 기반 Text-to-Music 대비 성능 향상 및 학습시간 단축을 이뤄냈습니다.
Model architecture of FluxMusic
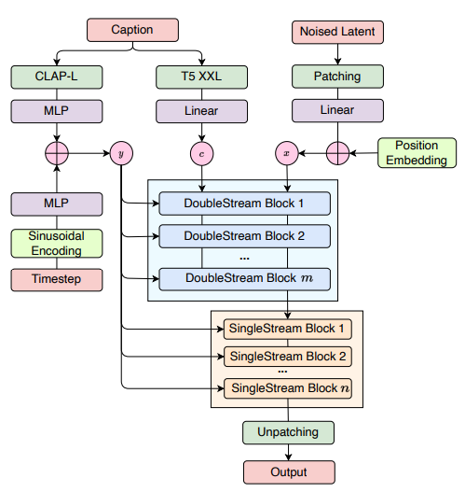
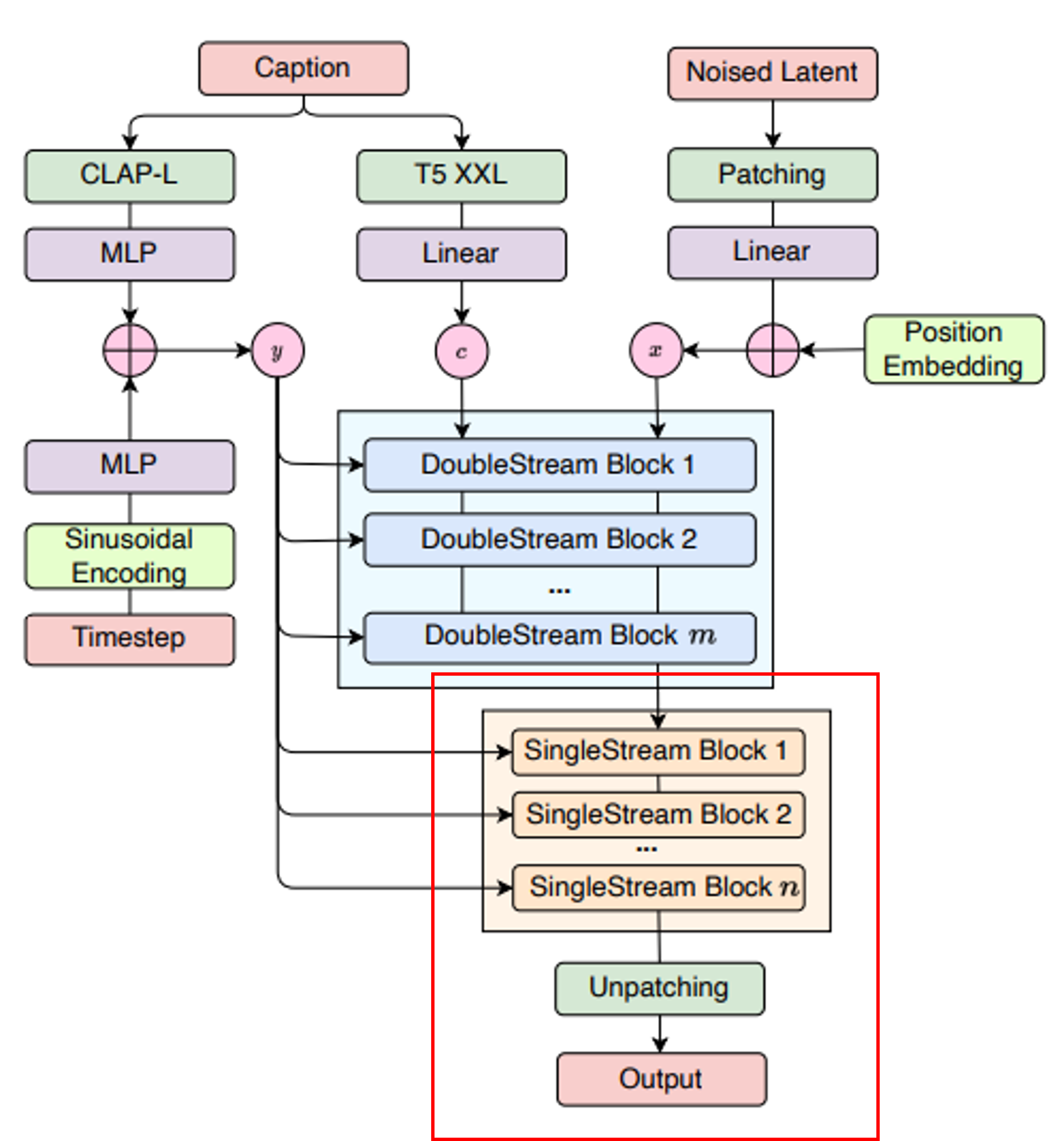
[그림 1] Model architecture of FluxMusic
논문 소개에서 바로 모델 구조에 대해 이야기합니다. 부분 별로 간략하게 이야기하고 이론적인 이야기는 Methodology에서 이야기하겠습니다.
-
Caption
[그림 2] Model architecture of FluxMusic
이 부분에서는 사전 학습된 인코더를 사용하여 입력 텍스트 특징을 추출합니다.
-
CLAP-L : 입력 텍스트에서 Coarse한 텍스트 특징 y를 추출합니다. y는 Sinusodidal Encoding을 통해 시간 단계와 결합되어 Modulation 메커니즘에서 사용됩니다.
-
T5-XXL : 입력 텍스트에서 Fine-grained한 텍스트 특징 c를 추출합니다. c는 음악 시퀀스 x와 결합되어 모델의 주요 입력으로 사용됩니다.
“A calm and relaxing ambient track with soft piano and guitar” 예를 들어 이런 문장이 입력으로 들어오면 CLAP-L은 “calm”, ”relaxing”같은 키워드를 통해 전반적인 분위기 파악하고, T5-XXL은 “soft piano”와 “guitar”같은 구체적이고 세밀한 정보 제공합니다.
-
-
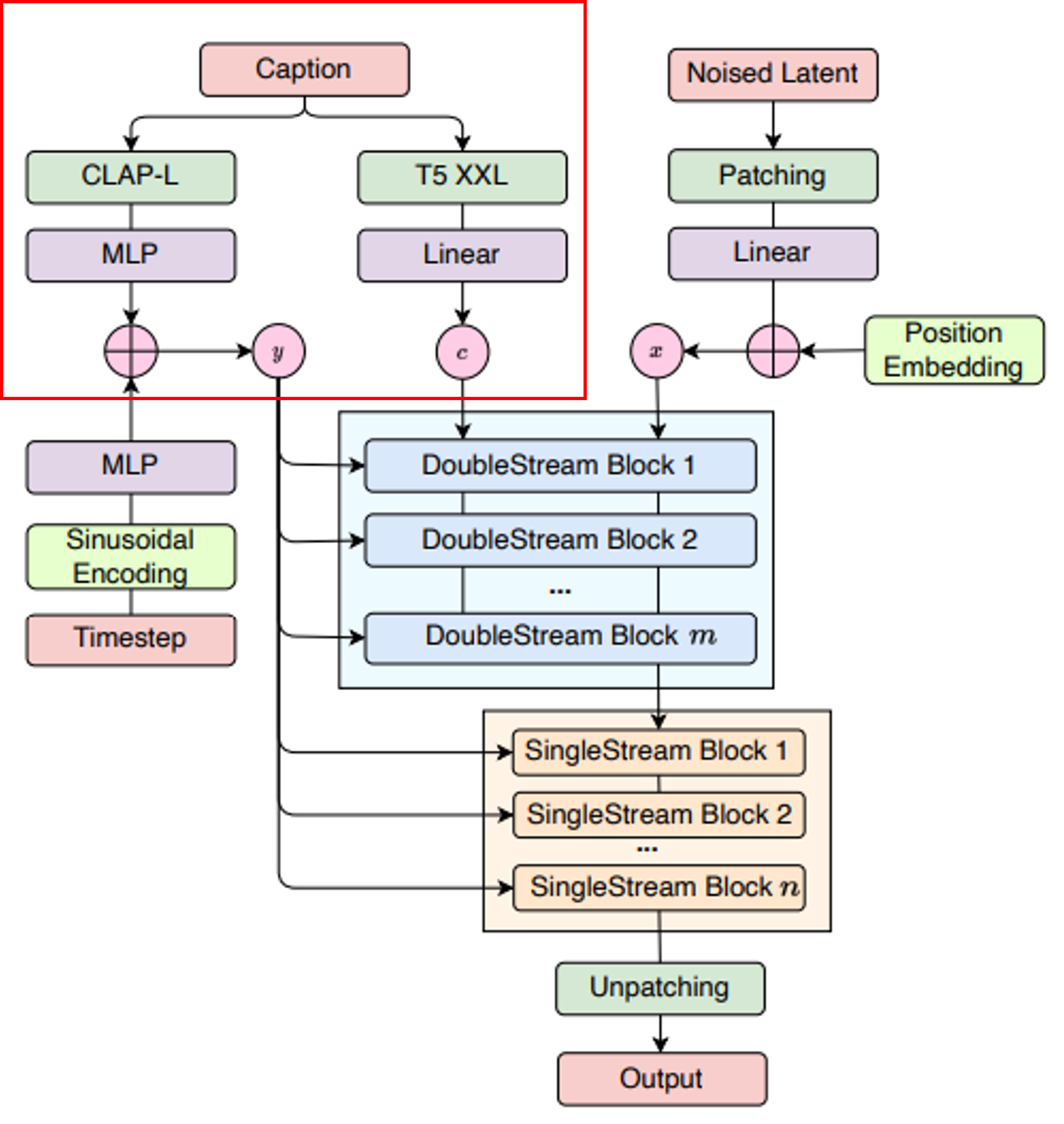
Noise Latent
[그림 3] Model architecture of FluxMusic
이 부분에서는 노이즈가 추가된 초기 음악의 잠재 표현이 입력으로 사용됩니다.
멜 스펙트로그램 형태로 표현되며 패치 처리와 Linear Transformation을 통해 모델에 입력됩니다. 잠재 표현은 작은 패치로 나누어지고, Position Embedding을 통해 각 패치에 위치 정보를 추가하게 됩니다. 이를 통해 모델이 공간적 순서를 이해하고 도와줍니다.
-
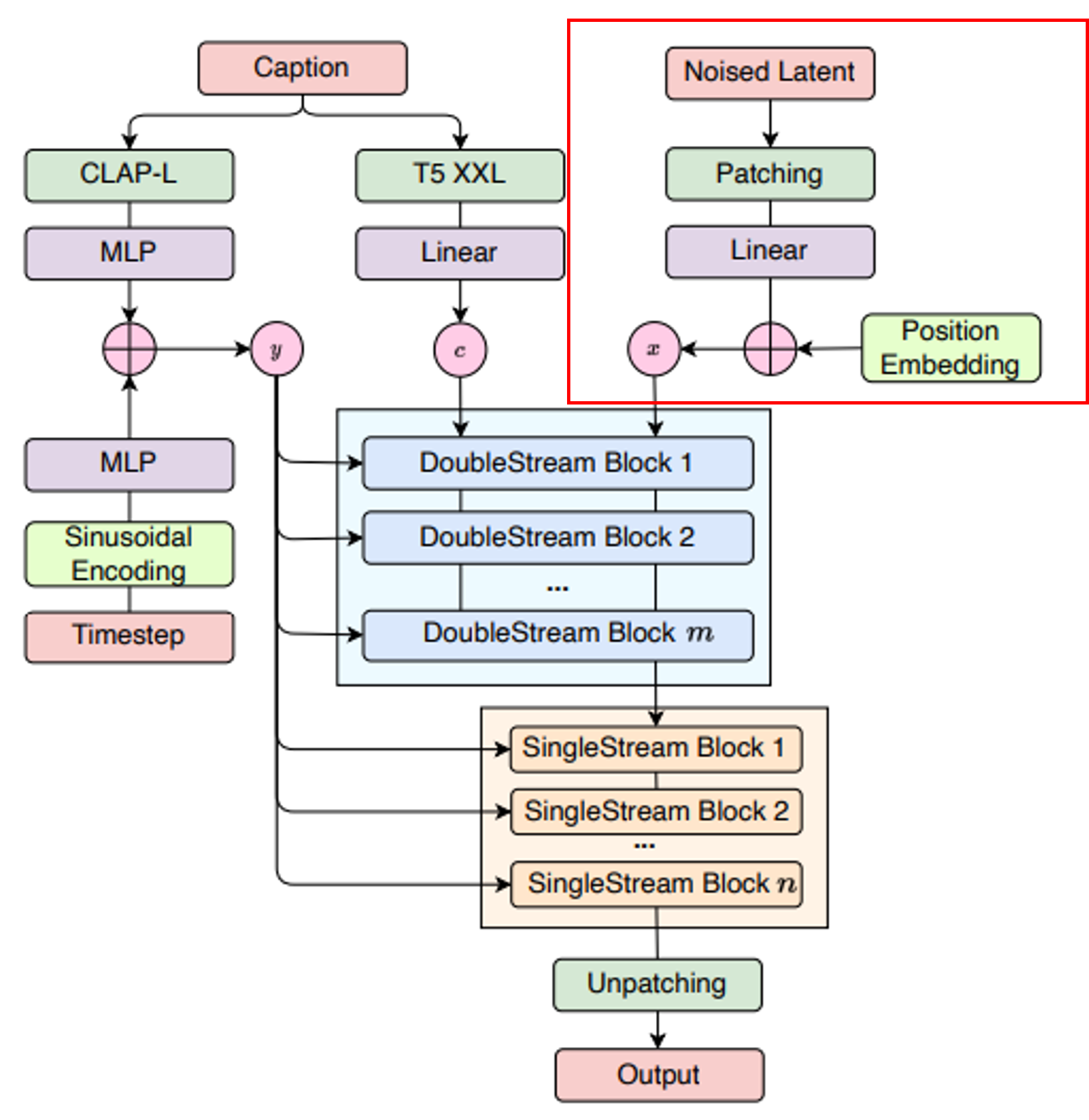
DoubleStream Blocks
[그림 4] Model architecture of FluxMusic
이 부분에는 m개의 DoubleStream Blocks가 스택으로 쌓여 있습니다. 텍스트와 음악 시퀀스를 병렬로 처리합니다. 텍스트와 음악 데이터를 독립적으로 학습한 뒤, Attention 메커니즘을 통해 두 데이터를 결합합니다.
이를 통해 텍스트와 음악 간의 상호작용을 학습하여 텍스트 조건에 맞는 음악 생성에 필요한 초기 정보를 제공합니다.
-
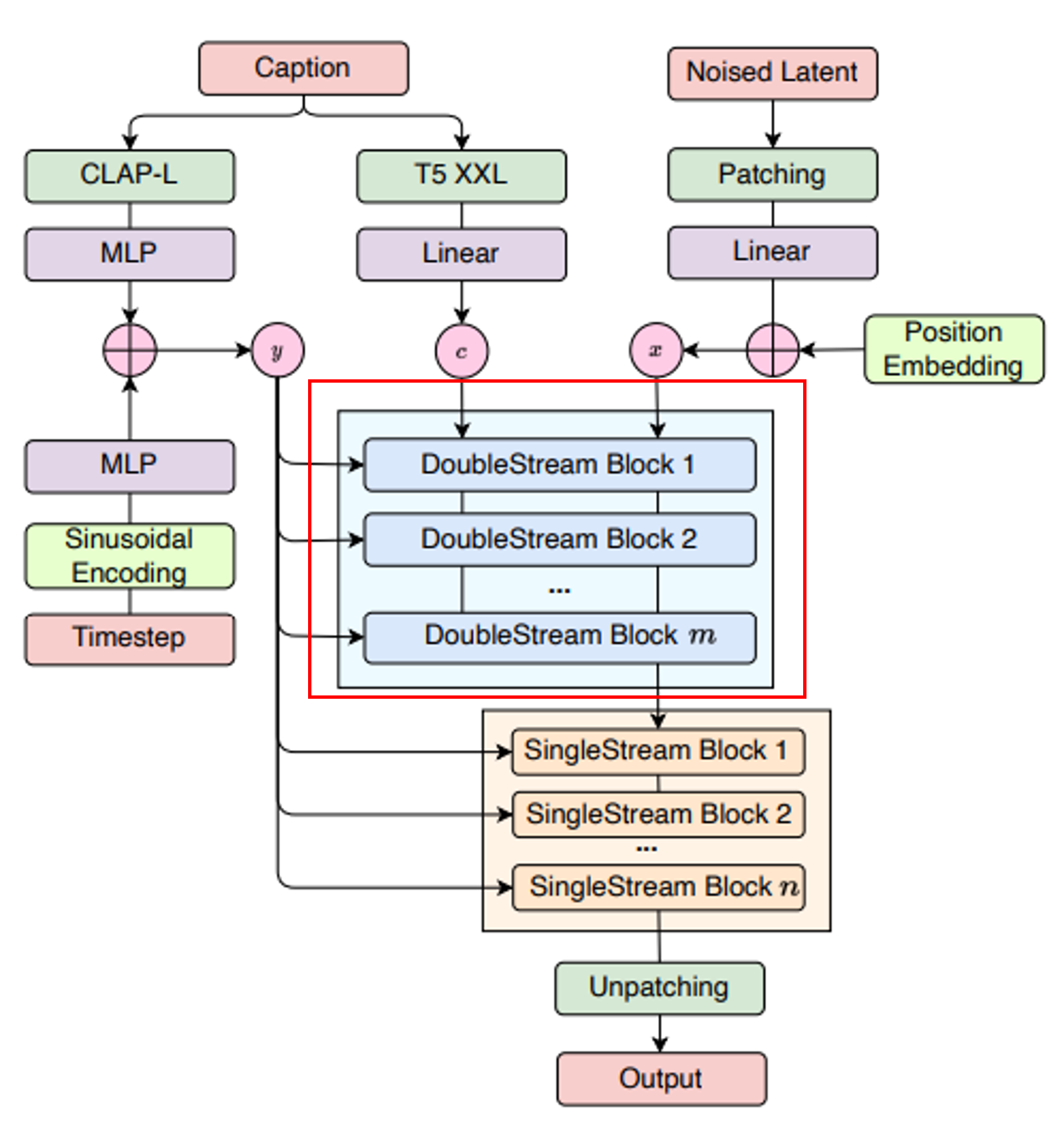
SingleStream Blocks
[그림 5] Model architecture of FluxMusic
이 부분에는 n개의 DoubleStream Blocks가 스택으로 쌓여 있습니다. 텍스트 스트림을 제거한 오직 음악 데이터만을 처리합니다. 이전 단계에서 결합된 텍스트-음악 정보를 바탕으로 노이즈를 제거하고, 점진적으로 깨끗한 음악 시퀀스를 생성합니다.
이를 통해 음악 데이터의 최종 예측과 denoising을 담당합니다. 다시 말해, 생성된 잠재 표현을 멜 스펙트로그램 형태로 복원하는 역할입니다.
최종 출력은 Vocoder를 통해 원본 오디오 파형으로 변환됩니다. 다른 확산 기반 모델과 마찬가지로 HiFi-GAN을 사용합니다.
Related Work
(관련 이론에서는 기존 음악 생성에 관한 역사를 이야기 하고 있습니다. 이 부분은 생략하고 모델과 연관된 이론만 적었습니다.)
Diffusion 포스트에서 설명 드렸듯이, 확산 모델은 기본적으로 U-Net 구조입니다. 하지만 FLUX 모델은 U-Net구조가 아닌 Transformer 를 사용합니다. 이것이 Diffusion Transformer 입니다.
Diffusion Transformer
Diffusion Transformer는 기존의 확산 모델의 U-Net 구조를 Transformer 구조로 대체한 모델입니다.
- 기존 확산 모델의 한계
U-Net은 CNN을 기반으로 하며, 데이터의 공간적 상관관계를 처리하는 데 적합하지만, 파라미터 확장이 어려우며 고해상도 데이터 생성에서 한계를 보입니다. 데이터에서 노이즈로, 노이즈에서 데이터로 변환하는 복잡한 프로세스 때문에 샘플링 속도가 느립니다.
- Diffusion Transformer의 개선점
데이터를 패치로 나누고, 이를 시퀀스 데이터로 처리하여 어텐션을 통해 패치 간의 관계를 학습합니다. U-Net보다 파라미터를 확장하기 쉽고, 더 복잡한 데이터 구조를 처리할 수 있습니다.
Methodology
Rectified Flow Trajectories
이 모델의 핵심 내용인 Rectified Flow 이야기입니다.
확산 모델은 데이터 분포 \(p_{0}(x)\) 에서 노이즈 분포 \(p_{1}(x)\) 변환하고, 그 역과정을 학습합니다.
\[z_t = (1 - t)x_0 + t\epsilon, \quad \epsilon \sim \mathcal{N}(0, I)\]여기서 \(z_{t}\) 는 \(p_{0}(x)\) 에서 \(p_{1}(x)\) 로 변환 되는 상태 벡터입니다. 이 벡터 경로가 Rectified Flow입니다.
\(\mathcal{p}_t(z_t)\) 는 \(z_{t}\) 가 시간 t에서 따르는 마진(Marginal) 확률 분포입니다.
\[\mathcal{p}_t(z_t) = \mathbb{E}_{\epsilon} [\mathcal{p}_t(z_t | \epsilon)]\]이 식은 \(z_{t}\) 가 주어진 시간 t에서의 상태 변화를 나타내는 방향과 속도를 결정합니다.
Rectified Flow는 아래 손실 함수를 통해 속도 필드(네트워크의 출력) \(v_\Theta(z, t)\) 를 학습합니다.
\[L = \mathbb{E}_{t, \mathcal{p}_t(z | \epsilon), \mathcal{p}(\epsilon)} \left[ \| v_\Theta(z, t) - u_t(z | \epsilon) \|^2 \right]\]Model Architecture
Introduction에서 이미 거의 다 언급을 하였지만 이야기 안 했던, 그리고 이 논문에서 가장 중요한 구조에 대해서 이야기해보겠습니다.
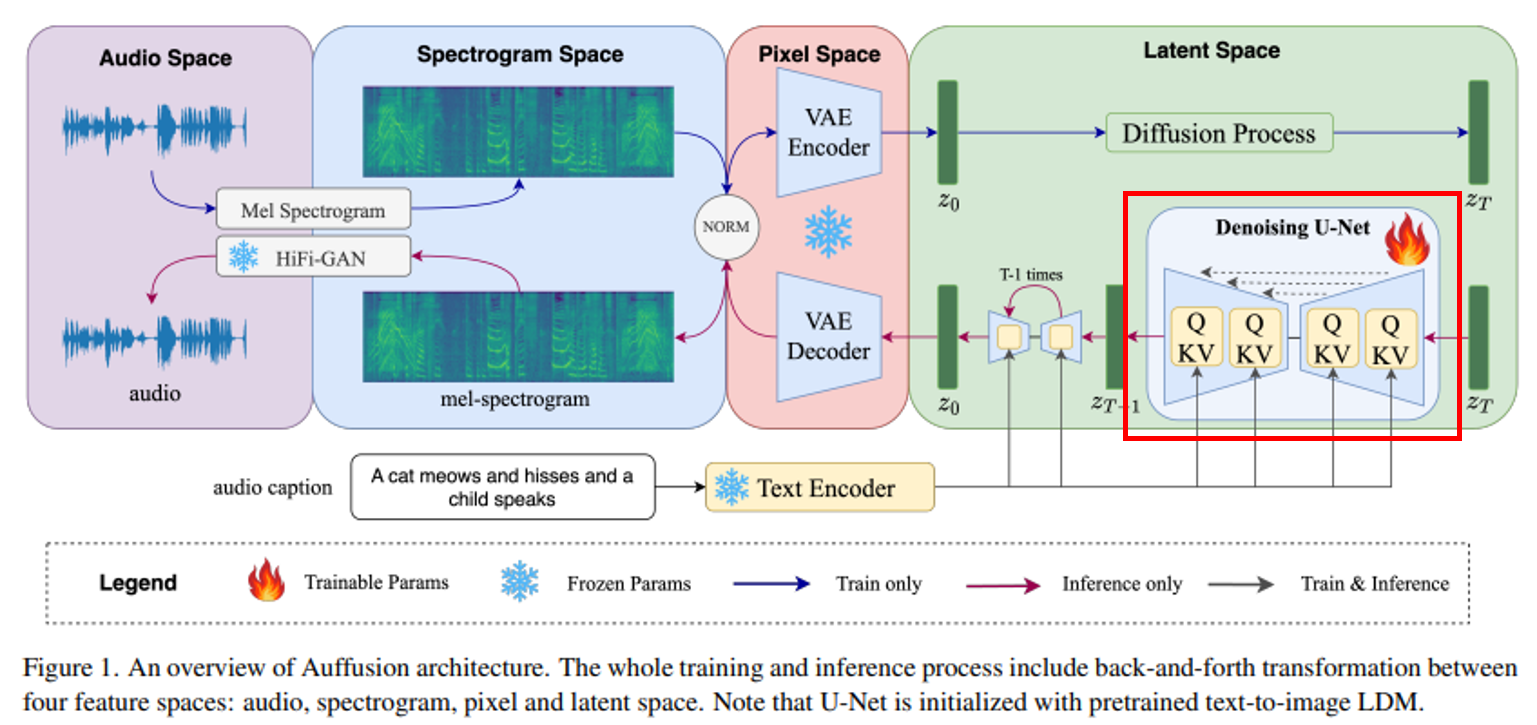
[그림 6] Diffusion 기반 모델 Auffusion 구조
기본적인 전체 구조 흐름은 같습니다.
멜 스펙트로그램이 VAE를 통과해서 압축된 잠재 표현으로 변환됩니다. 잠재 표현에 노이즈를 입힙니다. 그리고 역과정에서 노이즈를 제거하면서(Denoising) 학습합니다. 생성이 될 때에는 캡션 정보에 맞는 멜 스펙트로그램을 생성하고, 멜 스펙트로그램을 Vocoder(보통 HiFi-GAN을 많이 씁니다.)를 통해 원본 오디오 신호로 변환합니다.
위 그림은 Diffusion 기반 모델의 그림을 가장 잘 나타내는 논문 그림을 가져왔습니다. 여기서 Flux도 흐름은 같지만, 저 U-Net 구조가 트랜스포머 기반의 StreamBlock으로 바뀐 것입니다. 단순히 이 차이입니다.
이 모델은 10.24초 길이의 오디오 클립, Sampling rate는 16kHz입니다.(첨언: 나이퀘스트 샘플링 주파수 이론에 근거하면 생성 음원은 8kHz대역임을 유추할 수 있습니다.) VAE를 통해 압축된 멜 스펙트로그램 \(X_{\text{spec}} \in \mathbb{R}^{h \times w \times c}\) 을 2×2 패치로 분할합니다. (결론적으로는 \(\frac{1}{2}h\frac{1}{2}w\) 크기가 되겠죠.)
Disscussion
Methodology에서 Disscusion도 언급하고 있습니다.
- Model at Scale : 파라미터 수를 조정하여 성능과 계산 효율성 간의 균형을 유지할 수 있습니다. Transformer 레이어 수, 임베딩 차원, Attention 헤드 수를 조정하여 모델 크기를 구성할 수 있습니다. 이 논문에서는 아래 [표 1]과 같이 파라미터를 조절하여 모델 크기를 구성하였습니다.

[표 1] Scaling law of FluxMusic model size
- Synthetic data incorporation : 이 논문에서는 데이터 합성에 관한 이야기도 하고 있습니다. 대규모 텍스트-음악 데이터셋이 부족한 문제를 해결하기 위해 합성 데이터를 모델 학습에 활용하여 성능 강화를 하는 것이죠. 즉 FluxMusic을 이용하여 데이터를 증강하고 모델의 성능을 향상시키는 것에 대한 논의를 하고 있습니다.
Experiments
결과는 뻔합니다. 객관적, 주관적 지표 모두 FluxMusic이 좋았다!! 입니다. 실제로 현재 SOTA 2위를 기록하고 있는 모델이기도 합니다. 자세한 실험과 결과는 논문을 참고하시면 좋을 것 같습니다. 오늘 포스팅 여기서 마무리 하도록 하겠습니다. 감사합니다.
Follow my github
{kind=link}