HiFi-GAN 이란?
by DINHO
오늘 주제는 HiFi GAN입니다. HiFi는 high-fidelity의 줄임말로 “음향에서 원음과 원화에 충실한 재현”의 뜻을 갖고 있습니다. 오늘은 다음 논문의 내용을 리뷰하고 정리하여 HiFi GAN에 대하여 설명해보겠습니다. Kong, J., Kim, J., & Bae, J. (2020). Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis. Advances in Neural Information Processing Systems, 33, 17022-17033.
논문에서는 AR이나 플로우 기반 모델보다 더 높은 계산 효율성과 샘플 품질을 모두 달성하는 HiFi-GAN을 제안했습니다. 음성 오디오는 다양한 주기를 갖는 정현파 신호로 구성되므로 주기적인 패턴을 모델링하는 것이 사실적인 음성 오디오를 생성하는 데 중요합니다. 따라서 논문에서는 원시 파형의 특정 주기 부분만 얻는 작은 하위 판별자로 구성된 판별자를 제안했습니다. 이 구조는 사실적인 음성 오디오를 성공적으로 합성하는 모델의 기반입니다. 판별자를 위한 오디오의 서로 다른 부분을 추출하면서 다양한 길이의 패턴을 각각 관찰하는 여러 잔차 블록을 병렬로 배치하는 모듈을 설계하고 이를 생성기에 적용합니다. 그럼 본격적으로 개념과 이론들에 대해 알아보겠습니다.
Overview
HiFi GAN은 생성기(Generator) 1개와 판별기(Discriminator, 다중 스케일 및 다중 기간 판별기) 2개로 구성됩니다. 생성자와 판별자는 훈련 안정성과 모델 성능을 향상시키기 위해 두 가지 추가 손실과 함께 대립적으로 훈련됩니다.
-
Generator
생성기의 전체적인 내용은 다음과 같습니다.
생성기(Generator)는 fully convolutional neural network입니다. 입력으로는 멜-스펙트로그램을 사용하고 출력 시퀀스의 길이가 원시 파형의 시간 해상도와 일치할 때까지 전치된 컨볼루션(transposed convolutions)을 통해 업샘플링합니다. 모든 전치된 컨볼루션 뒤에는 다중 수용 필드 융합(Multi-receptive Field Fusion, MRF) 모듈이 뒤따릅니다.
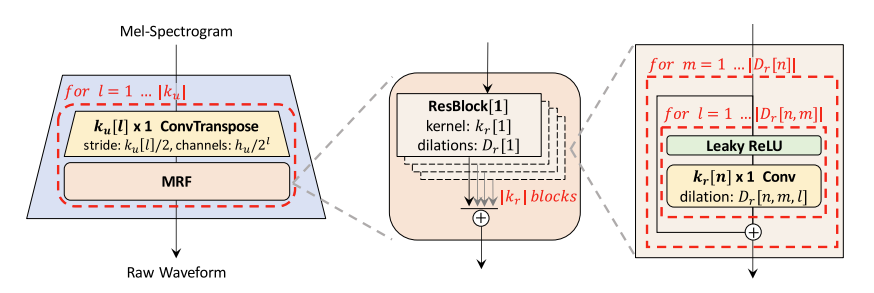 이미지 출처: 논문 그림1
이미지 출처: 논문 그림1그림1은 생성기의 구조를 보여줍니다. 이전 연구(Mathieu et al., 2015, Isola et al., 2017, Kumar et al., 2019)에서와 같이, 생성기에서는 노이즈가 추가 입력으로 제공되지 않습니다.
생성기는 멜-스펙트로그램을 \(\vert k_{u} \vert\) 배까지 업샘플링 합니다. \(\vert k_{u} \vert\) 는 원시 파형의 시간적 해상도와 일치하는 시간입니다. MRF 모듈은 다양한 커널 크기와 팽창률의 잔차 블록 \(\vert k_{r} \vert\) 의 특징을 추가합니다.
구조에 대해서 구체적으로 설명하겠습니다.
Transposed Convolutions
입력 : 멜-스펙트로그램이 초기 입력으로 사용됩니다.
전치된 컨볼루션 : 네트워크는 일련의 전치 컨볼루션 레이어를 통해 멜-스팩트로그램을 업샘플링합니다. 이러한 레이어는 타겟 원시 파형의 해상도와 일치하도록 입력의 시간 해상도를 점진적으로 증가시킵니다.
- 커널 크기 \(k_{u}[l]\) : 전치된 컨볼루션 레이어의 필터 크기입니다.
- Stride : Stride는 필터가 입력을 가로질러 이동하는 정도를 나타냅니다. 이 생성기의 경우 입력을 점진적으로 업샘플링하기 위해 커널 크기의 절반으로 설정됩니다.
- 채널 : 각 전치 컨볼루션마다 출력 채널 수가 \(h_{u} / 2^{l}\) 만큼 줄어들고 출력 시퀀스의 길이가 늘어납니다.
Multi-Receptive Field Fusion (MRF) Module
MRF 모듈 : 각 전치 컨볼루션 후에 출력은 MRF 모듈을 통해 전달됩니다. 이 모듈은 네트워크가 다양한 길이의 패턴을 관찰하고 결합하여 생성된 오디오의 풍부함과 다양성을 더할 수 있는 중요한 역할을 합니다.
- 잔차 블록 : 각 MRF 모듈은 여러 개의 잔차 블록으로 구성됩니다. 이러한 블록은 짧은 시간 패턴에서 긴 시간 패턴까지 광범위한 오디오 특징을 캡처하기 위해 다양한 커널 크기 \(k_r\) 과 팽창률 \(D_r\) 을 가지고 있습니다.
요약하자면 MRF 모듈 내의 모든 잔차 블록의 출력을 합산하여 다양한 수용 필드 패턴을 병합합니다.
Residual Block Structure
Residual Block :
- Dilated Convolution : 각 잔차 블록 내에는 파라미터 수를 크게 늘리지 않고도 수용 필드를 확장하는 데 도움이 되는 확장 컨볼루션 (Dilated Convolution) 레이어가 있습니다. 조정 가능한 파라미터 히든 레이어 \(h_u\) , 전치된 컨볼루션의 커널 크기 \(k_u\) , 커널 크기 \(k_r\) 및 MRF 모듈의 팽창률 \(D_r\) 은 합성 효율성과 샘플 품질 간의 요구 사항에 맞게 조절될 수 있습니다.
- Leaky ReLU : 활성화 함수로 Leaky ReLU 함수가 적용됩니다. 이 비선형 활성화 함수는 훈련 중에 그래디언트 흐름을 유지하는 데 도움이 되며 dying ReLU (ReLU 소멸)을 방지하는 장점이 있습니다. (ReLU는 읍수 입력에 대해 0을 출력하고, Leaky ReLU는 음수 입력에 대해 0.01을 곱하기 때문에 대부분 모델에서는 연산 속도를 빠르게 하기 위해 ReLU를 적용합니다. 하지만 이 모델에서는 속도보다 ReLU소멸을 방지하는 데 초점을 둔 것 같습니다. 개인적인 의견입니다. 😉😉)
-
Discriminator
long term dependencies를 식별하는 것은 사실적인 음성 오디오를 모델링하는 데 핵심입니다. 예를 들어, 음소 지속 시간이 100ms보다 길면 원시 파형에서 2,200 개 이상의 샘플에서 인접 샘플들끼리만 높은 상관 관계가 나타날 수 있습니다. 이 문제는 이전 연구(Donahue et al., 2018)에서 생성기와 판별기의 수용 필드를 증가시켜 해결되었습니다. 이 논문에서는 아직 해결되지 않은 또 다른 중요 문제에 초점을 맞추었습니다.
음성 오디오는 다양한 주기를 갖는 정현파 신호로 구성되므로 오디오 데이터의 기본이 되는 다양한 주기 패턴을 식별해야 합니다. 이를 위해 이 논문에서는 입력 오디오의 주기적 신호의 일부를 처리하는 여러 개의 서브 판별기로 구성된 MPD(Multi-Period Discriminator)를 제안했습니다. 또한, 연속 패턴과 long term dependencies을 캡처하기 위해 MelGAN(Kumar et al., 2019)에서 제안된 MSD(Multi-Scale Discriminator)를 사용하여 다양한 수준에서 오디오 샘플을 연속적으로 평가합니다. 이 논문에서는 MPD와 MSD가 주기적인 패턴을 포착하기 위해 간단한 실험을 수행했고 결과를 확인했습니다.
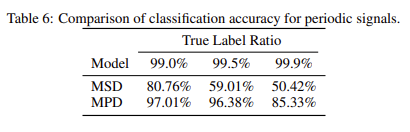 이미지 출처: 논문 표6.
이미지 출처: 논문 표6.구조에 대해서 구체적으로 설명하겠습니다.
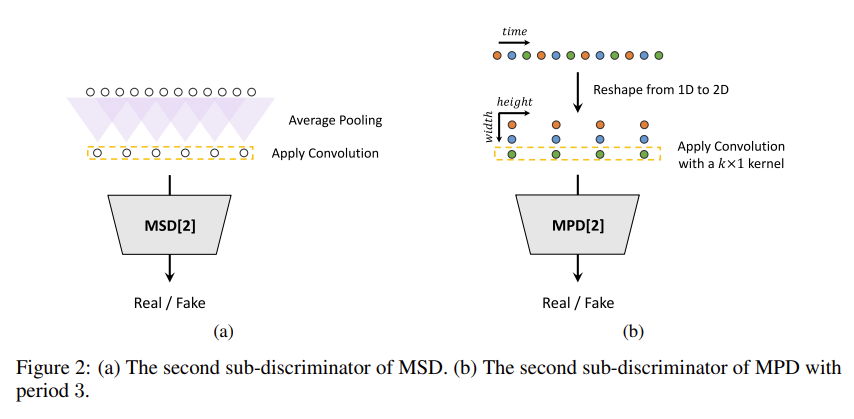 이미지 출처: 논문 그림2
이미지 출처: 논문 그림2Multi-Scale Discriminator(MSD)
MSD는 오디오 샘플을 서로 다른 스케일에서 평가하여 연속적인 패턴과 장기 의존성을 포착합니다.
Average Pooling : 원시 오디오 파형에 평균 풀링(Average Pooling)을 적용하여 다양한 스케일의 입력을 생성합니다. 풀링은 오디오 샘플의 연속적인 부분에 대한 평균을 계산하여 입력의 차원을 줄이고, 더 긴 시간 범위의 패턴을 포착할 수 있도록 합니다.
Apply Convolution : 평균 풀링된 오디오에 합성곱을 적용하여 특징을 추출합니다. 이 합성곱 레이어들은 오디오 데이터의 시간적 구조를 분석하는 데 사용됩니다.
Sub-discriminator : 여러 개의 서브 판별자가 각각 다른 스케일에서 오디오 샘플을 평가합니다. 이는 원시 오디오, 2배 평균 풀링 오디오, 4배 평균 풀링 오디오 등 다양한 해상도에서 오디오의 진위를 판별합니다.
Real/Fake Discrimination : 각 서브 판별자는 오디오가 실제인지 생성된 것인지를 판별합니다. 판별 결과는 생성기의 학습을 지도하는 데 사용됩니다.
Multi-Period Discriminator(MPD)
MPD는 입력 오디오의 다양한 주기적 특성을 식별하기 위해 설계되었습니다. 서로 다른 주기를 갖는 사인파 신호로 구성된 음성 오디오에서, 이러한 주기적 패턴을 식별하는 것이 중요합니다.
Reshape from 1D to 2D : 원시 오디오 파형을 주기 p에 따라 2차원 데이터로 재형성합니다. 이는 오디오의 주기적 특성을 2차원 평면에서 분석하기 위한 전처리 단계입니다.
Apply 2D Convolution : 재형성된 2차원 데이터에 2차원 합성곱을 적용하여 주기적 샘플을 처리합니다. 합성곱의 커널 크기는 주기적 샘플을 독립적으로 처리하기 위해 폭 방향으로는 1로 제한됩니다.
Sub-discriminator : 주기 p에 따라 다른 주기적 신호를 처리하는 여러 서브 판별자가 있습니다. 각 서브 판별자는 입력 Leaky ReLU를 사용하는 strided convolutional layers의 스택입니다.
Real/Fake Discrimination : 각 서브 판별자는 입력된 오디오의 주기적 특성을 바탕으로 실제 오디오인지 생성된 오디오인지를 판별합니다.
MPD는 원시 파형의 주기적 샘플에 집중하는 반면, MSD는 더 평활화된 파형에서 작동합니다. MPD는 주기적인 구조를, MSD는 연속적인 오디오의 특성을 감지하는 데 초점을 맞춥니다. 이 두 판별기 구조는 결합되어 생성된 오디오가 실제 오디오와 구분하기 어려울 정도로 진짜 같은 특성을 가지도록 하는 데 기여합니다. MPD에는 가중치 정규화가 적용되고, MSD에는 스펙트럴 정규화가 적용되어 각각의 판별자가 안정적으로 훈련될 수 있도록 합니다.
-
Training Loss
이제 HiFi GAN 손실 함수에 대해 설명하겠습니다. 여기서는 두 가지 주요 구성 요소로 이루어져 있습니다: 생성기(Generator, G)와 판별기(Discriminator, D).
GAN Loss : 이 모델은 LSGAN(Mao et al., 2017)의 방식을 따릅니다. 여기서는 원래 GAN의 목적 함수에서 사용되는 이진 교차 엔트로피를 최소 제곱 손실 함수로 대체하여 기울기가 사라지지 않는 흐름을 유지합니다. 판별기(D)는 진짜 샘플을 1로, 생성기(G)에서 합성된 샘플을 0으로 분류하도록 훈련됩니다. 생성기(G)는 판별기를 속이기 위해 합성 샘플의 질을 거의 1에 가깝게 분류되도록 개선합니다. 생성기와 판별기의 GAN 손실은 식 (1)과 (2)로 정의됩니다.
(2).png)
여기서 x는 실제 오디오, s는 실제 오디오의 멜-스펙트로그램인 입력 조건을 나타냅니다.
Mel-Spectrogram Loss : GAN 목적 외에도, 생성기의 훈련 효율성과 생성된 오디오의 충실도를 개선하기 위해 멜-스펙트로그램 손실을 추가합니다. Mel-Spectrogram Loss (멜-스펙트로그램 손실 함수)는 식 (3)으로 정의됩니다. 생성기(G)에 의해 합성된 파형과 실제 파형의 멜-스펙트로그램 사이의 L1 거리로 정의됩니다. 멜-스펙트로그램 손실은 입력 조건에 해당하는 현실적인 파형을 합성하는 데 도움을 주며, 적대적 훈련 과정을 초기 단계에서 안정화시키는 데에도 도움을 줍니다.
.png)
여기서 Φ는 파형을 해당 멜 스펙트로그램으로 변환하는 함수입니다.
Feature Matching Loss : 특징 매칭 손실은 판별기(D)의 특징 사이의 차이에 의해 측정되는 학습된 유사성 메트릭입니다. 실제 샘플과 생성된 샘플 사이의 판별기의 각 중간 특징을 추출하고, 각 특징 공간에서 실제 샘플과 조건부 생성된 샘플 사이의 L1 거리를 계산합니다. 이 손실은 판별기의 특징 공간에서의 유사성을 기반으로 하며, 생성기의 훈련에 추가적인 손실로 사용됩니다.식 (4)로 정의됩니다.
.png)
여기서 T는 판별기의 레이어 수를 나타냅니다. \(D^{i}\) 와 \(N^{i}\) 는 각각 판별기의 \(i\) 번째 레이어에 있는 특징과 특징 개수를 나타냅니다.
Final Loss : 생성기와 판별기의 최종 목표는 식 (5)와 (6)로 정의되며, 여기서 λfm = 2, λmel = 45로 설정합니다. 판별기가 MPD와 MSD의 서브 판별기 집합으로 구성되어 있기 때문에, 식 (5)와 (6)은 서브 판별기에 대해 식 (7)과 (8)로 변환될 수 있습니다. 여기서 \(D_K\) 는 MPD와 MSD의 k번째 서브 판별기를 나타냅니다.
.png)
.png)
여기까지 HiFi GAN에 대해 정리해보았습니다. 굉장히 어려우면서도 오디오 생성의 기본이라 생각합니다. 오디오 생성 AI에 관심이 있으신 분들에게 도움이 되었으면 합니다😊😊
Follow my github
{kind=link}