Mel-Spectrogram&MFCC 비교(with Cepstrum)
by DINHO
오늘은 멜-스펙트로그램(Mel-Spectrogram)과 MFCC에 대해서 이야기해보겠습니다!!
그러기 위해서 알아야 할 것!! 지난번 음성 신호 처리 기초에서 Envelop에 대해 공부했었죠? 마지막에 Cepstrum(캡스트럼)에 대해 이야기 해보겠다 했는데요. MFCC를 이해하기 위해서 Cepstrum의 개념이 필요합니다!! 이번 게시글에서 Cepstrum의 개념도 함께 공부해보도록 하겠습니다.
-
캡스트럼(Cepstrum)
\[1) s[n] = x[n]*h[n]\] \[2) S(f) = X(f)H(f)\]
이 사진과 공식 기억나시나요?? 기억이 안 나신다면 지난번 음성 신호 처리 기초 글을 꼭 읽고 오시길 바랍니다😁😁
여기서 결국 우리가 원하는 것은 Envelope을 구하는 것이었는데요!! 주파수 도메인에서 2번 식은 곱셈의 형태로 나타나 있는데 여기서 우리가 원하는 신호는 H(f)입니다.
X(f)는 빨리 변하는 Spectrum이므로 시간 축에서 빠릅니다. 따라서 고주파 영역의 신호라고 볼 수 있죠. 반대로 H(f)는 천천히 변하는 Spectrum이므로 시간 축에서 느립니다. 따라서 저주파 영역의 신호로 볼 수 있습니다. 이 때 단순히 S(f)신호에 Low-Pass Filter(LPF)만 적용한다고 H(f)를 구할 수 있을까요?? 구하지 못합니다. 왜냐하면 S(f)는 주파수 도메인에서 신호의 ‘곱셈’형태로 이루어져 있기 때문이죠.
그럼 이 곱셈을 덧샘으로 바꿔주면 간편하게 Low-Pass Filter(LPF)를 적용해서 H(f)를 구할 수 있을 것 같은데 어떻게 하면 좋을까요?? 바로 log를 도입하는 것입니다. 고등학교 수학 시간에 log의 덧셈을 배우셨죠?? 그 성질을 이용하는 겁니다!! 아주 간단한 원리이면서 획기적인 원리이죠😋😋
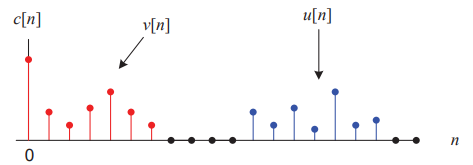
그래프와 같이 \(S(f) = X(f)H(f)\)였던 식이 \(c[n] = v[n] + u[n]\) 형태로 바뀐 것을 볼 수 있습니다.
즉, \(logS(f)\)의 Inverse FT을 \(c[n] = v[n] + u[n]\)으로 볼 수 있겠죠.
또한, \(logX(f)\)의 Inverse FT을 \(u[n]\)으로 나타낼 수 있고 이는 시간축에서 높은 영역입니다. 아울러 \(logH(f)\)의 Inverse FT을 \(v[n]\)으로 나타낼 수 있고 이는 시간 축에서 낮은 영역입니다.
이 때 c[n]을 S(f)의 Cepstrum(캡스트럼)이라고 합니다. Spec-trum(스펙트럼)에서 철자만 바꿔서 Ceps-trum(캡스트럼)이라고 말장난한 겁니다🤣🤣 그래서 위 그림에서 u[n]은 High-Time Cepstrum, v[n]은 Low-Time Cepstrum으로 볼 수 있겠죠?!!
우리가 주파수 도메인에서 특정 주파수 대역의 스펙트럼만 통과시키는 과정을 Filtering이라고 하죠?? Cepstrum에서는 Liftering이라고 합니다. 마찬가지로 Filt-ering에서 Lift-ering으로 철자만 바꿔서 말장난한 겁니다😂😂
마지막으로 n은 어떤 도메인일까요?? 주파수는 영어로 frequency라고 하죠? Cepstrum에서는 quefrency라고 합니다ㅋㅋㅋㅋㅋㅋㅋㅋㅋ 이건 좀 억지이지 않나 싶네요😅😅
-
MFCC(Mel-Frequency Cepstral Coefficient)
 이미지 출처: https://ratsgo.github.io/speechbook/docs/fe/mfcc
이미지 출처: https://ratsgo.github.io/speechbook/docs/fe/mfcc그렇다면 이제 본격적으로 오디오 특징 중 하나인 MFCC에 대해서 이야기 해볼까요? MFCC는 오디오 신호에서 추출할 수 있는 feature로, 소리의 고유한 특징을 나타내는 수치입니다. 전공 지식을 좀 더 섞어서 이야기 하면 “비선형 멜 스케일 주파수에 대한 로그 전력 스펙트럼의 선형 코사인 변환을 기반으로 사운드의 단기 전력 스펙트럼을 표현한 것들을 집합적으로 구성하는 계수”입니다. 너무 어렵죠🙄🙄 좀 더 쉽게 이야기 하면 멜-주파수를 캡스트럼적 분석을 통해 얻은 계수 오디오 특징이라고 생각하시면 편할 것 같습니다. 이를 이해하기 위해서는 멜-스케일(Mel-Scale)이 뭔지도 알아야 합니다. 차근차근 설명해드리겠습니다.
- Mel-Scale
주파수의 단위는 Hz입니다. 이 Hz 단위를 Mel 단위로 변환하는 것을 Mel-Filtering이라고 합니다.
Mel-Scale frequency는 사람의 귀를 모델링해서 만든 단위입니다. 사람의 귀는 선형적이지 않습니다. 고주파에서 둔감하고 저주파에서 민감합니다. 즉 높은 주파수의 소리일수록 사람은 잘 인지하지 못합니다. 이는 우리의 귀가 log 스케일에 더 적합하다는 뜻이겠죠?? 따라서 아래 공식처럼 기본 주파수 Hz 단위에 인간의 귀에 친화적인 log 스케일을 적용한 것을 Mel-Scale이라고 합니다.
\[Mel{x} = 2595 \times log_{10}(1 + x/700)\]다시 천천히 요약하자면 MFCC란 음성 신호의 스펙트럼을 Mel-Scale로 변환해주고 Cepstrum 분석을 통해 얻은 계수!! 이러한 오디오 특징을 MFCC라고 하는 것입니다.
-
Mel-Spectrogram
MFCC를 이해하셨다면 Mel-Spectrogram은 껌입니다!! 기존에 음성 신호 처리 기초에서 알려 드렸던 스펙트로그램 기억하시죠?? 여기서는 frequency 단위를 쓰는데, 이 단위를 Mel-Scale로 바꿔주기만 하면 Mel-Spectrogram이 됩니다!! 아주 쉽죠 :) 😎😎
그렇다면 이제 각각의 특징들을 비교해보겠습니다
Mel-Spectrogram vs Spectrogram
 이미지 출처: https://wikidocs.net/193588
이미지 출처: https://wikidocs.net/193588
Spectrogram
- 시간에 따른 신호의 주파수 내용을 정확하게 보여줌
- 음성 신호뿐만 아니라 음악, 환경 소리 등의 분석에 유용함
Mel-Spectrogram
- 음성 인식 같은 프로그램에 자연스러운 처리 가능
- 낮은 주파수에 중점을 두어 불필요한 정보를 줄이므로 효율적임
Mel-Spectrogram vs MFCC
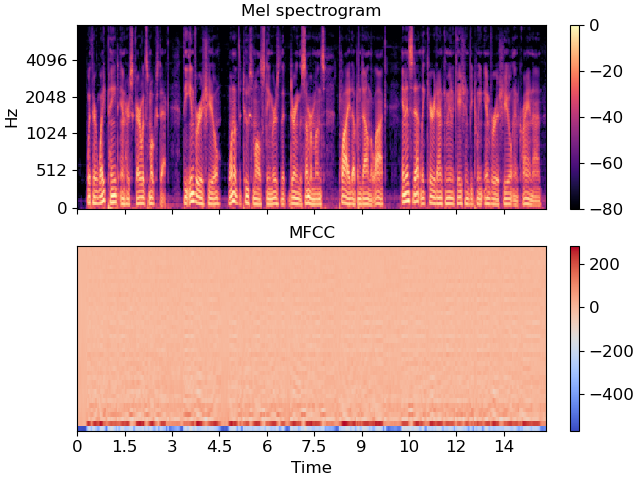
Mel-Spectrogram
- Correlate 관점에서 주파수 성분 간 상관 관계를 직관적으로 보여줌
- 고주파의 세부 정보가 손실될 수 있고, 상관 관계가 높은 데이터는 정보가 중복될 수 있어서 특정 응용 분야에 문제가 될 수 있음
MFCC
- De-correlate관점에서 각 계수가 독립적인 정보를 담기 때문에 데이터를 효율적으로 처리할 수 있음. 음성 인식 분야에서 매우 유용
- 노이즈가 많은 데이터에 대해 성능이 좋지 않음
- 계산이 복잡하여 추가적인 계산 리소스를 필요
특징들이 잘 정리 되셨나요?? 저는 비교를 통해서 더 잘 정리되는 느낌이었습니다. 아직도 이해가 안 가시는 분들을 위해!! 압축 또 압축해서 마지막으로 정리해드리자면
소리의 시각적인 분석이 필요할 때는 Mel-Spectrgram, 음소분할 같은 독립적 분석이 필요할 때는 MFCC 라고 생각하시면 편할 것 같습니다.
Cepstrum에 대한 내요은 신호 처리 전공 지식이 좀 필요했지만, 스펙트로그램, 멜 스펙트로그램, MFCC의 비교는 전공자가 아니더라도 최대한 이해할 수 있도록 작성해보았습니다. 제가 있는 연구실에서 진행 중인 협력 과제에서 신호 처리 전공을 배우시지 않은 의대 교수님께도 공유 된 내용입니다. 그만큼 정말 비전공자도 이해할 수 있도록 만든 내용입니다.
보통 이러한 특징은 오디오 AI모델에서 전처리 단계에 쓰입니다. 어떠한 전처리 과정을 거치냐에 따라 AI의 성능은 천차만별이 될 수 있습니다. 최근 나온 오디오 생성형 AI인 Auffusion이나 AudioLDM2같은 모델에서는 멜-스펙트로그램을 이용하고, 제가 리뷰했던 과비음 측정 딥러닝 알고리즘에서는 MFCC를 이용하였습니다. 상황에 맞게 알맞은 전처리 과정을 거치는 것이 중요한 만큼 각각의 특징들을 잘 이해하고 알맞게 적용하시길 바랍니다☺☺
ps) 오늘 게시글에서 출처 표기를 하지 않은 이미지는 광운대학교 인공지능 신호 처리 전공 수업에 사용된 이미지입니다.
긴 글 읽어 주셔서 감사합니다😉😉
Follow my github
{kind=link}