음성 신호 처리 기초
by DINHO
오늘은 음성 신호 처리에 대해서 이야기해볼까 합니다😄
대부분의 생성형 오디오 AI 모델이 학습을 할 때 소리를 이미지로 바꾸는 전처리 과정을 거쳐 학습합니다. 이러한 전처리 기술은 오디오 데이터를 더 의미 있는 형태로 변환하여 AI 모델이 효과적으로 학습하고, 더 정확한 예측을 할 수 있도록 도와줍니다. 오디오 신호의 복잡성을 줄이면서 중요한 특징을 추출하는 것이 주요 목적입니다.
이 포스트에서는 전처리 과정을 거치기 위해 어떤 지식을 알아야 하는지 이야기해보겠습니다. (기본적으로 관련 전공 수업 중 ‘신호 및 시스템’이나 ‘디지털 신호 처리’ 수업의 내용을 알고 있다고 생각하겠습니다.)
스펙트로그램(Spectrogram)
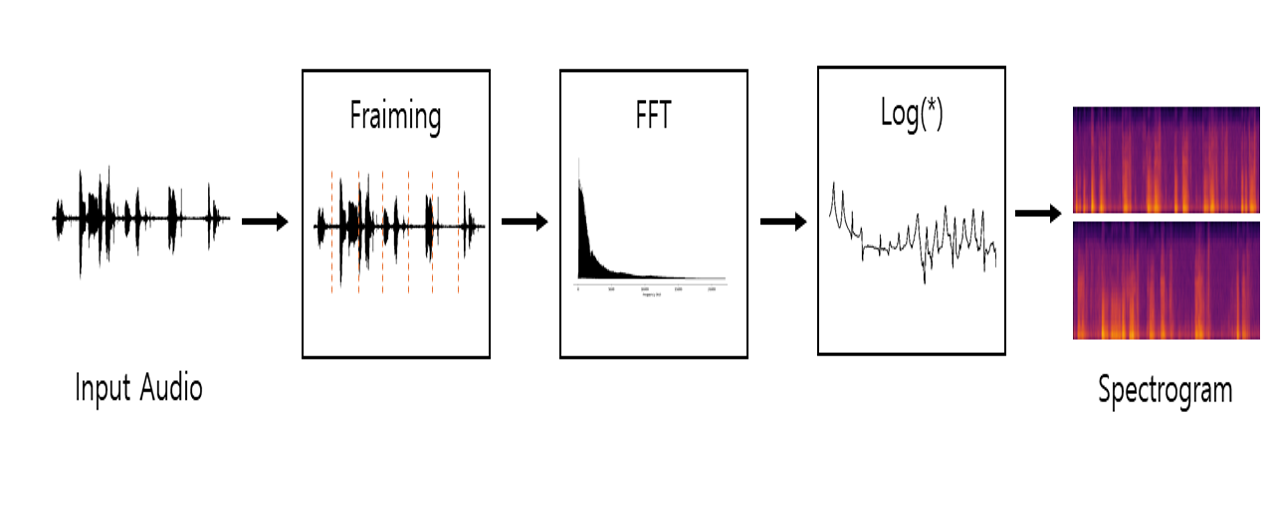
스펙트럼은 소리나 파동을 시각화하여 파악하기 위한 도구로, 파형(waveform)과 스펙트럼(spectrum)의 특징이 조합되어 있습니다. 시간 진행에 따른 음 높이(기본 주파수)의 변화를 볼 수 있고 소리들의 특징을 알 수 있습니다.
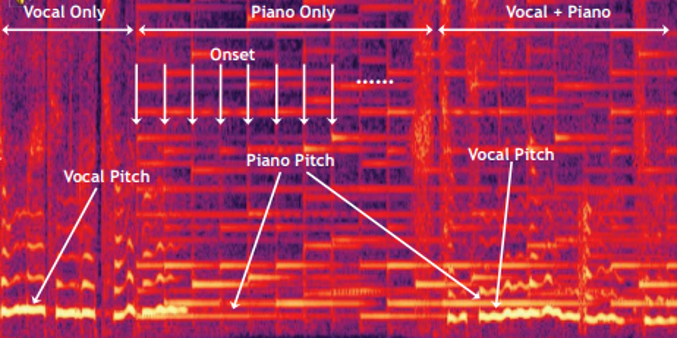
스펙트럼(Spectrum)

소리에서 스펙트럼은 소리의 특성을 한 눈에 알아볼 수 있습니다. 스펙트럼을 이용해 기본 주파수와 함께 배음구조를 파악할 수 있습니다. 여기서 배음구조는 뭘까요??
배음 구조
음악에서 옥타브(Octave)라는 개념을 아시나요? 어떤 가수는 음역대가 3옥타브 라까지 올라간다 이런 말을 들어보셨을 겁니다.
한 옥타브가 높다는 건 기본적으로 같은 음이지만 더 높게 소리가 들립니다. 기본 주파수 상으로는 2배 차이가 납니다.
1 옥타브를 12개의 반음(Semi-tone)으로 Geometric 균등 분할하면 그림과 같이 주파수를 계산할 수 있습니다.
\[반음\,주파수\,간격 = \sqrt[12]{a}\]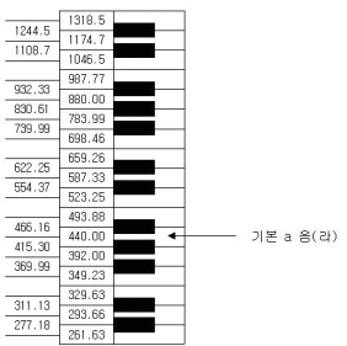
포먼트(Formant) & Envelope
위에서 봤던 스펙트럼 이미지에서 화살표에 해당하는 부분이 포먼트(Formant)입니다. 포먼트는 소리가 공명되는 특정 주파수 대역입니다. 사람의 음성은 성대(vocal folds)에서 형성되어 성도(vocal track)를 거치며 변형되는데, 소리는 성도를 지나면서 포먼트(Formant)를 만나 증폭되거나 감쇠됩니다. 즉, 포먼트(Formant)는 배음(harmonics)과 만나 소리를 풍성하게 혹은 선명하게 만드는 필터 역할을 한다고 볼 수 있습니다.
여기서 포먼트들을 이은 선을 Envelope이라고 합니다. 한 마디로 사람의 음성 신호를 아래 사진과 수식처럼 표현할 수 있습니다.

아까 사람의 음성은 성대에서 형성되어 포먼트를 만나 증폭되거나 감쇠된다고 했죠?? 이 말을 듣고 1번 식을 떠올리셨다면 전공 수업 중에 ‘신호 및 시스템’이나 ‘디지털 신호 처리’라는 과목을 매우 잘 수강하신 분이라 생각됩니다😁 신호는 입력 신호와 응답 신호의 컨볼루션 곱으로 표현할 수 있습니다. 즉. 음성 신호에 적용하면 음성은 성대에서 나온 여기 신호(Excitation)와 포먼트 필터의 컨볼루션으로 표현할 수 있습니다.
이 수식에 퓨리에 변환(Fourier transform)을 적용하면 2번식과 같이 주파수 도메인에서 일반 곱의 형태로 나타낼 수 있고, 그림과 같이 이해할 수 있습니다.
즉, 우리의 목표는 음성 신호에서 포먼트를 이은 부분, 다시 말해 Envelope을 구해야 음성의 특성을 알 수 있겠죠?? 단순히 주파수 도메인에서 필터를 적용해도 두 신호의 곱 형태이기 때문에 원 신호와 차이가 있습니다.
그래서 다음 게시글에서는 Envelope을 어떻게 구할 것인가!에 대한 Cepstrum 내용을 다루어보겠습니다.
오늘 내용은 음성 신호처리의 기초를 다루어 봤습니다. 컨볼루션 곱이나 퓨리에 변환 같은 경우는 ‘신호 및 시스템’이나 ‘디지털 신호 처리’ 같은 전공 과목을 수강하셔야 알 수 있는 내용입니다. 신호 처리나 인공 지능을 공부하시는 분이라면 이 글을 이해하시는 데 어려움이 없으실 것이라 생각합니다. 출처 표기를 하지 않은 이미지는 광운대학교 인공지능 신호 처리 전공 수업에 사용된 이미지입니다. 제가 과거에 들었던 수업 내용인데 다시 복습 한다는 마음으로 자료를 다시 들여다 봤더니 기억이 새록새록하네요😚😚
Follow my github
{kind=link}