ETTA: Elucidating the Design Space of Text-to-Audio Models리뷰
by DINHO
오늘은 Sang-gil Lee, et al. “ETTA: Elucidating the Design Space of Text-to-Audio Models” 논문을 리뷰하겠습니다.
INTRODUCTION
Text-to-Audio(TTA)모델의 셜계 공간은 복잡하며, 수많은 상관 관계가 있는 요인이 포함됩니다. 이 논문에서도 설계 공간과 각 요인의 기여도를 이해하려고 시도했지만, 실험 간 결론 도출을 하는 데에는 실패했습니다.
이 논문에서는 TTA 모델을 구축하기 위한 기존 패러다임의 전체적인 이해를 제공하려고 합니다. 또한, 데이터와 모델 크기에 대한 확장성을 평가하는 것을 목표로 합니다. 새로운 모델이나 방법론을 제안하는 것이 아니라, 핵심적인 디자인 요소를 규명하고 더 나은 결과를 얻을 수 있는 요소를 확인하는 것입니다.
논문에서 이야기 하는 이 연구의 기여를 살펴보겠습니다.
-
AF-Synthetic이라는 대규모 고품질 합성 캡션 데이터셋을 소개하고, 밴치마크에서 TTA 생성 품질 향상 가능성을 보여줌
-
TTA 공간에서 주요 디자인 선택 사항을 분석하고, 데이터, 아키텍처 디자인, 훈련 목표, 샘플링 방법에 중점을 두고 벤치마크에서 점수를 개선하는 데 있어서 각 구성 요소의 중요성 설명
-
TTA를 위한 Diffusion transformer(DiT)의 개선된 구현을 소개
-
공개 데이터세트에서 훈련된 TTA 모델 ETTA를 제시
-
복잡하고 상상력이 풍부한 캡션에 따라 창의적인 오디오를 생성하는 ETTA의 개선된 기능 보여줌
Related Work
Diffusion and Flow Matching Based Model
논문에서는 확산 모델과 Flow Matching을 비교 분석하여 최적의 방법을 찾았습니다. 먼저 두 가지 주요 패러다임을 설명합니다.
-
Diffusion 모델: 가우시안 노이즈를 점진적으로 깨끗한 데이터로 변환하는 역확률적 과정을 학습
-
Flow Matching 모델: 분포 간 최적 전송과 관련된 벡터 필드를 예측
이러한 모델들은 효율성, 확장성, 품질 향상을 위해 latent space에서 훈련될 수 있습니다. (Flow Matching에 대한 내용은 다음에 이야기해보도록 하겠습니다.)
Text-to-Audio Models
TTA 연구는 크게 두 가지 접근법으로 나뉩니다.
Diffusion/Flow Matching 기반 접근법
오디오 생성: Liu et al., Ghosal et al., Huang et al. 등의 연구
음악 생성: Melechovsky et al., Evans et al., Schneider et al. 등의 연구
다양한 구조와 훈련 설계가 제안되었으니, 체계적인 비교 연구는 부족합니다.
언어 모델 기반 접근법
여기서 이야기하는 언어 모델은 Transformer입니다. AudioGen, MusicGen, MusicLM등이 대표적입니다.
이 모델들은 오디오의 이산 토큰 표현에 대해 다음 토큰 예측을 수행하는 방식입니다.(MusicGen 에서 이야기한 적 있습니다.😀)
본 논문의 연구 범위와는 직교적인 접근입니다.
Synthetic Data for Improved TTA
오디오-캡션 데이터셋은 다양한 형태로 발전 과정을 거쳐왔습니다. 최근에는 TTA 개선을 위한 합성 데이터를 이용한 방법을로 중요한 발전을 거쳤습니다.
-
Sound-VECaps: 시각적 설명과 소리 설명을 결합하여 캡션 생성
-
한계: 비디오가 없는 오디오에는 적용 불가, 과도한 시각 정보 포함 가능
-
Tango-AF: Audio Flamingo를 사용한 AF-AudioSet으로 훈련
-
한계: 품질은 높지만 규모가 매우 작음
-
GenAU: AutoCap으로 생성된 캡션으로 훈련
이러한 연구들은 합성 캡션이 TTA 품질을 크게 향상시킬 수 있음을 입증하였습니다.
핵심 시사점
논문에서는 Related Work에서 이야기한 연구들이 다양한 설계 선택을 제안했지만, 이들 간의 체계적인 비교가 부족했다고 지적합니다. 특히
-
설계 공간에 탐색해야 할 변수가 너무 많음
-
데이터셋 간 공정한 비교가 어려움
-
각 요소의 기여도가 명확하지 않음
이러한 문제의식을 바탕으로 본 논문은 diffusion/flow matching 기반 TTA 모델의 설계 공간을 체계적으로 연구하는 최초의 시도임을 강조합니다.
Methodology
-
AF-Synthetic
데이터셋 파이프라인
-
Audio Flamingo(Kong et al., 2024)를 사용하여 각 오디오 샘플에 대해 10개의 캡션 생성
-
CLAP 유사도 기반 선택: 생성된 10개 캡션 중 오디오와 가장 높은 CLAP 유사도를 가진 캡션 선택
-
유사도 임계값: 0.45 이상 (AF-AudioSet 연구에서 최적값으로 확인)
-
임계값 미달 시 해당 캡션 폐기
-
대규모 확장을 위한 개선사항
-
세그먼트 단위 처리: 긴 오디오를 겹치지 않는 10초 세그먼트로 분할하여 처리
-
품질 필터링: “noisy”, “low quality”, “unknown sounds” 등의 키워드로 저품질 오디오 탐지
-
서브샘플링: 음악과 음성을 제외한 긴 오디오 세그먼트는 서브샘플링 적용
최종 데이터셋 규모
-
총 135만 개의 고품질 캡션 생성
-
데이터 출처: AudioCaps, AudioSet, VGGSound, WavCaps, Laion-630K
-
MusicCaps와 중복 없음
-
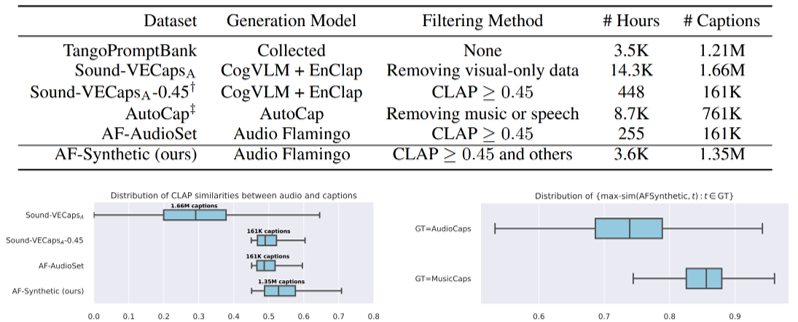
[그림 1] Overview of our proposed AF-Synthetic dataset
-
ETTA
### ETTA-VAE: 오디오 압축을 위한 변분 오토인코더
#### 아키텍처 세부사항
-
입출력 사양: 44.1kHz 샘플링 레이트의 스테레오 오디오 처리
-
모델 크기: 156M 파라미터로 구성된 대규모 VAE
-
압축 비율:
-
원본 오디오: 44,100Hz → Latent space: 21.5Hz
-
약 2,050:1의 시간축 압축률 달성
-
64차원 latent vector로 표현
-
#### 훈련 세부사항
-
손실 함수 구성:
-
Multi-resolution STFT loss (스펙트로그램 공간에서 거리 측정)
-
Adversarial hinge loss와 feature matching loss (Encodec 스타일)
-
KL divergence loss (posterior를 N(0,I)에 근사)
-
-
훈련 데이터: Table 12에 나열된 40개 이상의 공개 데이터셋 활용
-
최적화: AdamW optimizer, learning rate 1.5×10⁻⁴, exponential decay
### ETTA-LDM: Latent 공간에서의 Diffusion 모델
#### Diffusion Transformer (DiT) 백본
-
레이어 구조:
-
24개의 transformer blocks
-
각 블록당 24개의 attention heads
-
Hidden dimension: 1536
-
총 1.44B 파라미터 (최적 구성)
-
-
Cross-attention 메커니즘: T5 텍스트 임베딩과 latent audio features 간 상호작용
#### T5 텍스트 인코더 통합
-
모델 선택 근거:
-
T5-base: 110M 파라미터의 encoder-decoder 모델
-
다양한 길이의 텍스트 처리에 유연함
-
-
토큰화 전략:
-
최대 512 토큰까지 처리 (기존 연구들은 주로 128-256 사용)
-
AF-Synthetic의 긴 캡션들을 온전히 활용 가능
-
-
임베딩 처리: Variable-length text embeddings를 cross-attention으로 주입
### ETTA-DiT 핵심 개선사항 상세 분석
#### 1. Adaptive Layer Normalization (AdaLN) 구현
기존 방식 (Stable Audio Open):
-
Timestep embedding을 prepending 방식으로 처리
-
일부 레이어에만 적용
ETTA-DiT 개선:
-
모든 레이어 입력에 AdaLN 적용:
-
Self-attention 입력
-
Cross-attention 입력
-
Feed-forward network 입력
-
-
초기화: scale=1, bias=0 (초기에는 modulation 없음)
-
FP32 정밀도 강제로 수치적 안정성 확보
-
Unbounded gating (sigmoid 없음) → 더 넓은 표현 범위
#### 2. 최종 레이어 초기화 전략
문제점: 랜덤 초기화 시 VAE latent 분포와 불일치
해결책:
-
Final projection layer의 가중치를 0으로 초기화
-
초기 출력이 VAE latent의 평균(0)과 일치
-
결과: 훈련 초기 안정성 대폭 향상, 수렴 속도 개선
#### 3. 추가 아키텍처 개선사항
GELU Activation 최적화:
-
Tanh 근사 모드 사용:
tanh(√(2/π) × (x + 0.044715x³)) -
정확한 GELU 대비 계산 효율성 향상
Rotary Position Embedding (RoPE):
-
Base frequency: 16,384
-
일반적인 설정(512-2048)보다 훨씬 큰 값
-
긴 시퀀스에 대한 외삽(extrapolation) 능력 향상
-
-
적용 범위:
-
텍스트: 최대 512 토큰
-
오디오 latent: 215 프레임 (10초 @ 21.5Hz)
-
-
FP32 정밀도: RoPE 연산 시 수치적 정확도 보장
Dropout 정규화:
-
확률: 0.1 (모든 모듈에 적용)
-
목적:
-
파라미터 추정의 견고성 향상
-
벤치마크를 넘어선 실제 캡션에 대한 일반화 능력 개선
-
-
Trade-off: 250k 스텝에서는 약간 낮은 점수, 장기적으로는 더 안정적
### 구현상 주요 고려사항
-
메모리 효율성: Flash Attention 2 사용으로 학습 처리량 최대화
-
혼합 정밀도 훈련: BF16 사용 (AdaLN과 RoPE는 FP32)
-
초기화 전략: 각 구성요소별 맞춤형 초기화로 훈련 안정성 확보
-
모듈성: VAE와 LDM을 독립적으로 훈련 가능한 구조
이러한 개선사항들의 조합으로 ETTA-DiT는 기존 Stable Audio Open 대비 훈련 손실이 지속적으로 개선되며, 1M 스텝까지도 안정적인 학습이 가능함을 입증했습니다.
-
-
훈련 목표 및 샘플링 (Section 3.3)
## 훈련 목표 함수 및 샘플링 전략 상세 분석
### 훈련 목표 함수: Diffusion vs Flow Matching
#### V-prediction Loss (Diffusion 모델)
# V-prediction 타겟 정의 v_target = √(α_t) * ε_t - √(1 - α_t) * x_0 # 여기서: # x_t: 노이즈가 추가된 시점 t의 데이터 # x_0: 원본 클린 데이터 # ε_t: 가우시안 노이즈 # α_t: 노이즈 스케줄 (variance schedule)V-prediction의 특징:
-
기존 ε-prediction이나 x-prediction 대비 수치적 안정성 우수
-
중간 timestep에서의 gradient가 더 균형적
-
Stable Audio Open에서 기본으로 사용하는 방식
#### OT-CFM Loss (Optimal Transport Conditional Flow Matching)
# OT-CFM 손실 함수 L_OT-CFM = E[||v_θ(x_t, t) - (x_1 - x_0)||²] # 여기서: # v_θ: 학습된 벡터 필드 # x_0: 노이즈 (source) # x_1: 클린 데이터 (target) # x_t: 선형 보간된 중간 상태Logit-normal t-sampling의 혁신:
# 기존 uniform sampling t ~ U(0, 1) # 모든 timestep 동일 확률 # ETTA의 logit-normal sampling z ~ N(0, 1) t = σ(z) # sigmoid 함수 적용 # 결과: 중간 timestep (t ≈ 0.5) 주변 집중 # 이유: 중간 단계가 학습에 가장 중요한 정보 포함실험 결과 비교:
-
V-diffusion: 500K 스텝 이후 불안정성 시작
-
OT-CFM + uniform: 안정적이나 수렴 속도 느림
-
OT-CFM + logit-normal: 1M 스텝까지 안정적, 최고 성능
### 샘플링 방법론 심층 분석
#### ODE 솔버 비교
Euler 방법 (1차):
# 단일 스텝 업데이트 x_{t-1} = x_t + dt * v_θ(x_t, t) # 장점: 빠른 계산, 메모리 효율적 # 단점: 낮은 NFE에서 정확도 떨어짐Heun 방법 (2차 Runge-Kutta):
# 예측-수정 방식 k1 = v_θ(x_t, t) x_pred = x_t + dt * k1 k2 = v_θ(x_pred, t-dt) x_{t-1} = x_t + dt * (k1 + k2) / 2 # 장점: 높은 정확도, 적은 NFE로도 좋은 품질 # 단점: 스텝당 2번 모델 평가 필요실험적 발견:
-
NFE < 50: Heun이 Euler보다 현저히 우수
-
NFE ≥ 100: 두 방법이 비슷한 성능으로 수렴
-
최종 선택: Euler with NFE=100 (효율성과 품질의 균형)
#### Classifier-Free Guidance (CFG) 최적화
CFG 수식과 구현:
# 조건부와 무조건부 예측 결합 v_guided = v(x_t, t, ∅) + w_cfg * (v(x_t, t, c) - v(x_t, t, ∅)) # w_cfg = 1: guidance 없음 (다양성 높음) # w_cfg > 1: 조건 강조 (품질 높음, 다양성 낮음)메트릭별 최적 CFG 스케일:
-
FD (Frechet Distance): w_cfg ≈ 3-4에서 최적 (convex 함수 형태)
-
KL, IS, CLAP: w_cfg 증가할수록 계속 개선
-
다양성 vs 정확도 트레이드오프:
-
w_cfg = 1: 높은 다양성, 낮은 텍스트 충실도
-
w_cfg = 3.5: ETTA의 선택 (균형점)
-
w_cfg = 7: Stable Audio Open 기본값 (과도한 조건 강조)
-
### Pareto 최적화 분석
#### 다차원 메트릭 최적화
품질 메트릭: - FD_P, FD_O: 분포 거리 (낮을수록 좋음) - KL_S, KL_P: 이벤트 분포 일치도 (낮을수록 좋음) - IS_P: Inception Score (높을수록 좋음) - CL_L, CL_M: 텍스트-오디오 정렬 (높을수록 좋음) 추론 속도: - NFE: 함수 평가 횟수 (낮을수록 빠름)Pareto 프론티어 발견:
-
빠른 추론 (NFE=20): Heun + w_cfg=2
-
균형잡힌 품질 (NFE=50): Heun + w_cfg=3
-
최고 품질 (NFE=100): Euler + w_cfg=3.5 ✓ (ETTA 선택)
### Autoguidance 실험 분석
작동 원리:
# 나쁜 모델을 이용한 가이던스 v_auto = v_bad(x_t, t) + w_ag * (v_good(x_t, t) - v_bad(x_t, t)) # v_bad: 작은 모델 또는 덜 훈련된 모델 # w_ag: autoguidance 강도실험 설정:
-
Bad 모델: XS (0.28B) 또는 50k/100k 스텝 체크포인트
-
w_ag 범위: 1.0 ~ 2.5 (0.25 간격)
-
CFG와 조합: w_cfg=1 또는 3과 함께 테스트
결과 분석:
-
다양성 증가: 주관적으로 더 흥미로운 샘플 생성
-
객관적 메트릭: CFG 단독 사용 대비 개선 없음
-
계산 비용: 2배 NFE 필요 (bad 모델 추가 평가)
-
결론: 창의적 생성에는 잠재력 있으나, 벤치마크 개선에는 비효과적
### 핵심 설계 결정의 상호작용
#### 데이터-아키텍처-훈련의 시너지
AF-Synthetic (135만 캡션) ↓ ETTA-DiT (개선된 안정성) ↓ OT-CFM + Logit-normal (효율적 학습) ↓ Euler + CFG (실용적 샘플링)#### 안정성 피라미드
-
기반: 고품질 합성 데이터 (CLAP > 0.45)
-
구조: 수치적 안정성 (AdaLN, FP32, 초기화)
-
학습: Flow matching (diffusion보다 안정적)
-
추론: 검증된 샘플링 전략
### 실용적 권장사항
프로덕션 배포 시:
-
실시간: NFE=20, Heun, w_cfg=2
-
고품질: NFE=100, Euler, w_cfg=3.5
-
창의적: NFE=50, Heun, w_cfg=1.5 + Autoguidance
미래 연구 방향:
-
Consistency distillation으로 NFE 감소
-
적응적 CFG (timestep별 다른 강도)
-
학습된 guidance 네트워크
이러한 체계적 접근을 통해 ETTA는 각 구성요소의 최적 조합을 발견했으며, 이는 공개 데이터만으로 proprietary 모델과 경쟁할 수 있는 성능을 달성하는 핵심이 되었습니다.
-
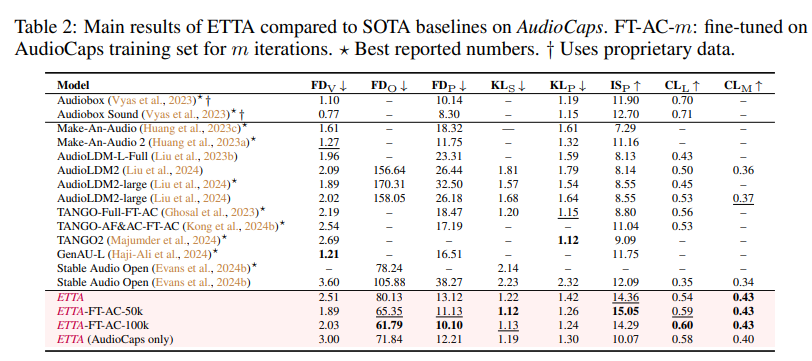
[그림 2] 실험 결과
실험 결과는 생략하겠습니다.
다음에는 Flow Matching에 대해 이야기해보도록 하겠습니다!!
Follow my github
{kind=link}