MusicGen 이란?
by DINHO
안녕하세요! 오늘은 MetaAI에서 공개한 MusicGen에 대해 알아보겠습니다. 이 모델은 아카이브에 공개된 “Simple and Controllable Music Generation(01.2024)” 논문에서 처음 소개했습니다. 오늘은 이 논문 리뷰를 하겠습니다. 먼저 간단하게 MusicGen에 대해 요약하여 설명 드리겠습니다.
MusicGen은 조건부 음악 생성의 경계를 재정의하는 강력한 단일 언어 모델로, 텍스트 설명이나 멜로디에서 단서를 얻어 고품질 음악을 생성합니다. 논문에서 다양한 연구를 통해 MusicGen이 기존 방식보다우수한 성능을 보인다고 주장하고 있습니다. 그렇다면 어떻게 그럴 수 있는지 자세히 논문을 살펴보겠습니다.
Introduction
논문의 소개에서는 Text-to-music에 대해 설명하고 이 과정에서 직면하는 몇 가지 주요 도전 과제와 논문의 기여를 다루고 있습니다.
-
Text-to-Music의 도전 과제
-
긴 시퀀스 모델링 : 음악은 Speech보다 긴 시퀀스를 필요로 하며, 전체 주파수 스펙트럼을 사용해야 함. 따라서 기존의 오디오 생성 AI에서 sampling rate가 16kHz인 반면 음악은 44.1kHz 또는 48kHz로 sampling rate를 설정해야 함.(Nyquist Theorem)
-
복잡한 구조 : 음악에는 다양한 악기의 하모니와 멜로디가 포함되어 있어 구조가 복잡함. 인간은 불협화음에 민감하기 때문에 작곡할 때 멜로디 오류를 만드는 경우가 적음.
-
제어 가능성 : 키, 악기, 멜로디, 장르 등 다양한 방법으로 작공 과정을 제어하는 능력은 작곡가에게 필수적임.
-
-
최근 연구
-
최근 Self-supervised audio representation learnig, Sequential modeling, Audio synthesis의 발전으로 복잡한 모델을 개발할 수 있는 조건을 제공함.
-
오디오 모델링을 보다 다루기 쉽게 만들기 위해 최근 연구에서는 오디오 신호를 동일한 신호를 나타내는 Multiple Streams of Discrete tokens을 제안함. 하지만 이 경우 여러 개의 병렬 종속 스트림을 공동으로 모델링해야 하므로 계산적 부담이 커집니다.
-
위 문제를 해결하기 위해 첫 번쨰 토큰 스트림만 모델링 하고 post-network를 적용하여 비자기 회귀 방식으로 나머지를 공동 모델링합니다.
여기서 잠깐!! Discrete tokens이란?
Discrete tokens란 음성 신호를 디지털화 하여 일련의 이산적인 기호나 코드로 변환한 것입니다. 미리 정의된 코드북에 의해 정의되며, 각 토큰은 특정한 오디오 패턴이나 특징에 매핑됩니다. 아래에서 또 설명하겠습니다.
-
-
논문의 기여
이 논문에서는 다음과 같은 기여를 했다고 주장합니다.
-
32kHz의 고품질 음악을 생성할 수 있는 간단하고 효율적인 모델을 제안.
-
단일 모델로 텍스트와 멜로디 기반의 생성 모두를 수행하며, 제공된 멜로디와 텍스트 조건에 충실한 일관된 음악을 생성할 수 있음.
-
Method
MusicGen은 텍스트나 멜로디 표현에 따라 조건화된 Autoregressive Transformer based Decoder(Vaswani et al., 2017)를 사용합니다. 이 모델은 EnCodec(Défossez et al., 2022) 오디오 토크나이저에서 생성된 양자화된 유닛들을 학습하며, 이 토크나이저는 낮은 프레임 속도에서 Hi-Fidelity의 오디오 재구성을 제공합니다.
-
Audio Tokenization
이미지-출처:assemblyai.com -
EnCodec(Défossez et al., 2022)은 Residual Vector Quantization(RVQ) 방식을 사용하여 오디오를 양자화된 토큰으로 변환합니다.
-
주어진 오디오 신호는 연속적인 텐서로 인코딩된 후 여러 개의 Parallel Discrete Token Sequence로 양자화 됩니다.
-
RVQ에서는 첫 번째 코드북이 가장 중요하며 각 코드북은 이전 양자화기의 오차를 인코딩 합니다.
위의 RVQ와 Discrete Token에 관한 내용은 링크 를 참고해주세요!
-
-
Codebook
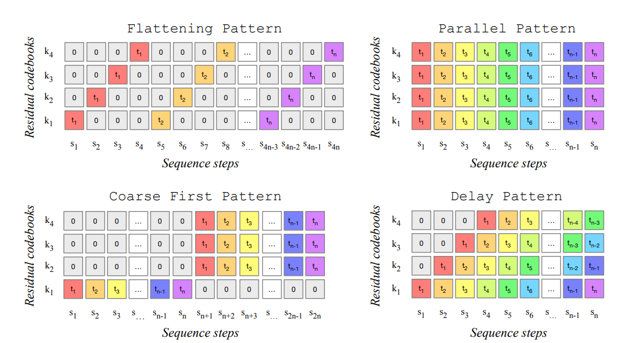
-
코드북(k1,k2,k3,k4): 이 모델에서 데이터를 처리할 때 오디오 신호는 여러 개의 코드북에서 양자화된 값을 가져옵니다.
-
각 시간 단계(t1,t2,t3,t4)마다 4개의 양자화된 값이 존재하며, 이는 k1,k2,k3,k4에 해당합니다.
-
각 시간 단계에서 코드북 값이 존재하기 때문에 이 값들을 어떻게 처리하는지가 중요합니다. 이 값들을 모델링하는 패턴 방법에 따라 시퀀스 길이가 달라지며, 시간 복잡도에 영향을 줍니다. 각 패턴에 대한 설명은 아래와 같습니다.
Flattening Pattern : 이 패턴에서는 각 시간 단계의 모든 코드북 값을 순차적으로 예측합니다. 이 방식은 모든 코드북을 하나의 긴 시퀀스로 취급하므로 시퀀스의 길이 S는 T*K가 됩니다.
정확한 모델링이 가능하다는 장점이 있지만 시퀀스 길이가 길어지므로, 연산량이 증가하며 계산 복잡도가 높아질 수 있습니다.
Parallel Pattern : 이 ㅐ턴에서는 각 시간 단계에서 모든 코드북 값을 병렬로 예측합니다. t1에서 k1, k2, k3, k4 값을 동시에 예측한 후 t2로 넘어가 같은 방식으로 진행하는 방법입니다. 이 방식은 시퀀스 길이를 T로 유지합니다.
더 빠른 학습과 추론이 가능하다는 장점이 있지만 병렬 예측으로 인해 모델링이 덜 정확할 수 있으며, 예측 오류가 축적될 가능성이 있습니다.
Coarse First Pattern : 이 패턴에서는 각 시간 단계에서 중요한 코드북(k1)부터 먼저 예측하고, 이후 나머지 코드북들을 병렬로 순차적으로 예측합니다. 이 방식은 중요한 정보를 먼저 모델링함으로써 예측 오류를 줄일 수 있습니다.
중요한 정보에 대한 우선적인 처리가 가능하다는 장점이 있지만 병렬 패턴에 비해 여전히 시퀀스가 길어질 수 있다는 단점이 있습니다.
Delay Pattern : 이 패턴에서는 각 코드북 간에 Delay를 도입하여 순차적으로 예측합니다.
시퀀스의 길이를 제어할 수 있으며 모델링 과정에서의 유연성을 제공한다는 장점이 있지만, 지연된 예측으로 인해 학습 속도가 떨어질 수 있으며, 여전히 오류가 축적될 가능성이 있습니다.
MusicGen 같은 경우는 Delay Pattern을 채택했습니다.
-
-
Model Conditioning
Text Conditioning
목적: 텍스트 설명을 기반으로 오디오를 생성할 때, 입력된 텍스트를 효과적으로 모델에 반영하기 위함
기법: 텍스트 설명을 토대로 \(C \in \mathbb{R}^{T_C \times D}\) 의 텐서를 계산합니다. C는 실수 값을 가지는 텐서입니다. \(T_C\) 는 조건 텐서 C의 시간 단계 또는 길이를 나타냅니다. \(T_C\) 는 텍스트나 멜로디와 같은 조건 신호를 인코딩 할 때 이 신호가 몇 개의 시간 단계로 나누어지는지를 나타냅니다. 예를 들어 텍스트가 여러 개의 단어로 이루어져 있다면 각 단어가 하나의 시간 단계로 인코딩 될 수 있습니다. D는 Autoregressive 모델에서 사용하는 내적 차원을 나타냅니다.
논문에서는 기존에 연구가 진행된 T5 인코더, FLAN-T5, CLAP를 각각 사용하여 실험했습니다.
Melody Conditioning
목적: 멜로디 구조를 기반으로 음악을 생성하기 위함
기법: 입력된 오디오의 크로마그램(Chromagram)과 텍스트 설명을 동시에 조건으로 사용해 멜로디 구조를 제어합니다. 크로마그램이란 소리의 12개 pitch를 기준으로 나타낸 특징입니다. 지난 음성 신호 처리 이론 게시글에서 배음 구조를 참고하시면 이해하기 편하실 겁니다.
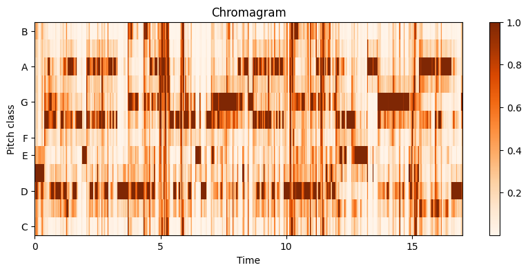
크로마 그램을 그대로 사용하면 원래 심플을 재구성하게 되어 과적합이 발생할 수 있습니다. 이를 방지하기 위해 논문에서는 시간 주파수 해상도(time-frequency bin)에서 가장 중요한 정보를 선택해 information bottleneck을 도입합니다. 수식은 아래와 같습니다. 이 수식을 이해하려면 정보이론에서 Mutal Information의 내용을 알고 있어야 합니다.
간단하게 말씀 드리면 latent T를 통해서 알게 된 input X의 정보량은 최소가 되면서 target Y를 통해서 알게 된 latent T의 정보량이 최소가 되어야 합니다. 입력한 데이터에서 중요한 정보만 마기기 때문에 모델이 데이터의 복잡한 패턴이나 노이즈를 지나치게 학습하지 않게 되어서 과적합을 방지할 수 있습니다.
\[\inf_{p(t|x)} \left( I(X; T) - \beta I(T; Y) \right)\] -
Model architecture
Codebook Projection and Positional Embedding
코드북 패턴: 코드북이 주어지면 각 패턴 단계 \(P_S\) 에서는 일부 코드북만 사용되고, 이 때 \(P_S\) 는 모델이 특정 시점에 어떤 코드북이 사용할 지 결정하는 단계입니다.
코드북 값 추출: 주어진 패턴 단계 \(P_S\) 의 인덱스에 해당하는 양자 벡터 값 Q를 추출합니다.
각 코드북은 특정 토큰 값을 가지며 벡터로 변환됩니다.
마지막으로 Positional Embedding을 추가하여 각 시퀀스에서 위치 정보를 제공합니다.
Transformer Decoder
구조: L개의 레이어와 차원 D로 구성된 트랜스포머 디코더입니다. 각 레이어는 Causal self-attention 블록으로 구성되며, 이 블록은 시퀀스 내에서 과거 정보만을 사용해 현재 값을 예측하는 데 사용됩니다.
Cross-Attention을 이용해 멜로디와 같은 외부 신호를 반영합니다. 멜로디 조건을 사용할 때는 조건부 텐서 C를 트랜스포머 입력의 prefix로 제공하여 모델이 입력 데이터를 처리하기 전에 조건을 반영하게 합니다.
Logits Prediction
트랜스포머 디코더에서 패턴 단계 \(P_S\) 의 출력은 다음 패턴 단계 \(P_{S+1}\) dp eogks logit prediction으로 변환됩니다. logit은 확률 분포를 예측하기 위한 입력 값으로, 여기서는 모델이 다음 코드북 값을 예측할 때 사용합니다.
조금 더 쉽게 구조를 아래와 같이 요약해보겠습니다.
초기 입력: 첫 번째 시간 단계에서 모든 코드북의 초기 값들이 주어짐
디코딩: 트랜스포머 디코더는 주어진 입력에 대해 다음 시간 단계에서의 로짓 값을 예측
샘플링: 예측된 로짓 값에서 상위 k개의 토큰 중 하나를 선택하여 다음 토큰을 결정함
반복: 이 과정을 반복하여 전체 시퀀스를 생성하며, 이때 새롭게 생성된 토큰은 다음 단계의 입력으로 사용
최종 음악 생성: 이러한 반복 과정을 통해 전체 오디오가 생성
-
실험 및 결과
학습에는 20k 시간의 licensed dataset을 사용했습니다. 테스트셋으로는 MusicCaps를 사용하였습니다. 파라미터 크기를 다르게 하여 여러 실험을 거쳤습니다.
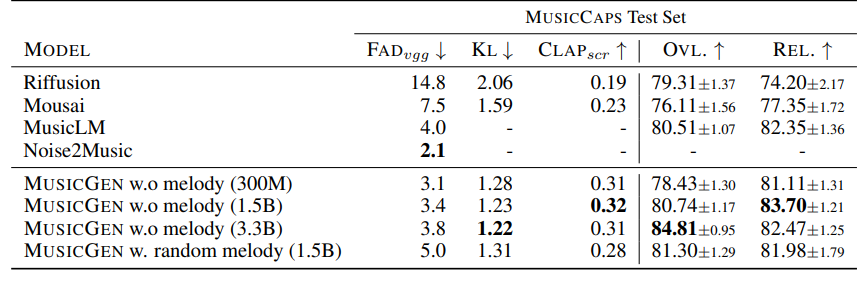
Diffusion 기반의 비교적 최근 모델인 AudiLDM2에서도 TTM모델들을 비교했는데요, 여기서는 AudioLDM2의 성능이 더 좋다고 주장하고 있습니다.
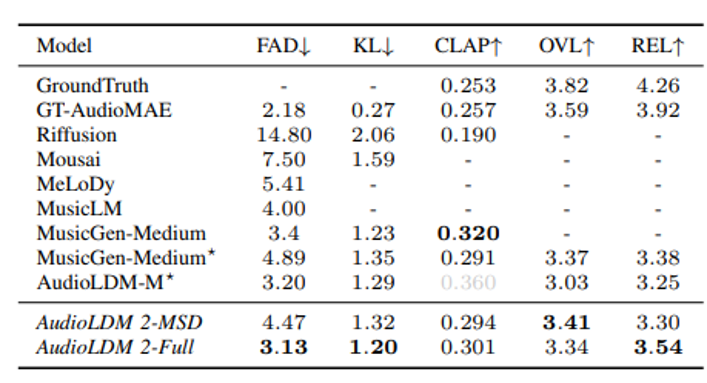
하지만 AudioLDM2는 다양한 모달리티의 목적성이 강합니다. MusicGen과 같이 긴 시퀀스와 넓은 주파수 대역에서의 음악 생성과는 거리가 좀 있습니다. 그래서 직접적으로 비교하기에는 무리가 있다고 생각합니다.

여기까지 MusicGen에 대한 리뷰를 마치겠습니다!! 감사합니다😊
Follow my github
{kind=link}