Transformer란?
by DINHO
오랜만에 논문 리뷰입니다. 지난 번 논문 리뷰 때 MusicGen 이야기를 했었는데요! MusicGen Decoder의 기반이 되기도 하고, 인공지능을 공부하는 사람이라면 절대로 몰라선 안 되는!!! Transformer, Attention Is All You Need(2017) 논문 리뷰를 해보겠습니다.
-
연구 배경
기존 RNN(Recurrent Neural Network)과 CNN(Convolutional neural network) 기반 모델은 긴 문맥을 학습하기 어렵고, 병렬처리가 어렵다는 단점이 있습니다. Transformer 모델은 이러한 문제를 해결하기 위해 고안되었습니다.
-
순환 구조 제거 : RNN의 순차적인 계산 방식을 없애고 병렬 처리가 가능하게 함으로써 학습 속도를 높임
-
Self-Attention : 입력의 각 단어가 다른 모든 단어와 직접 연결되어 긴 거리의 종속 관계를 쉽게 학습할 수 있도록 함.
-
-
Model Arcitecture
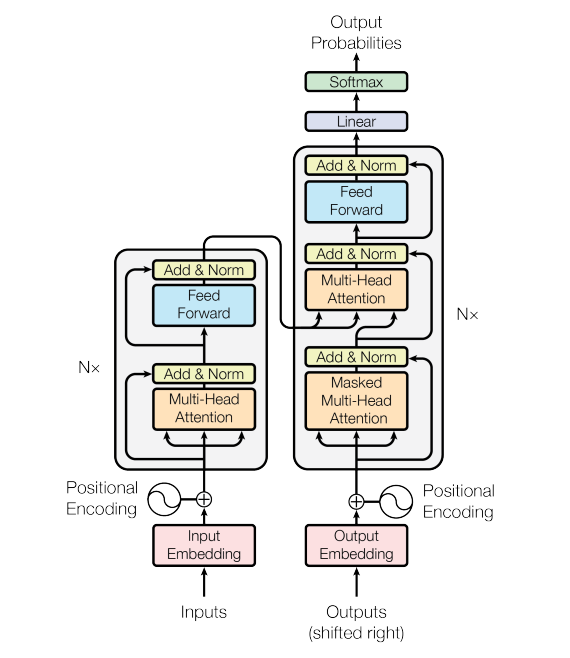 그림1 - 트랜스포머 모델 구조
그림1 - 트랜스포머 모델 구조Transformer는 인코더-디코더 구조를 따르며, 일반적인 Sequence to Sequence 작업에 적합하게 설계되었습니다. 그림의 왼쪽과 오른쪽 부분에 표시된 것처럼 인코더와 디코더 모두에 stacked self-attention and point-wise, fully connected layers를 사용하는 아키텍처를 따릅니다.
2.1 Encoder and Decoder Stacks
-
Encoder : 인코더는 동일한 레이어의 스택(Stack of identical layer)으로 구성되어 있습니다(일반적으로 N=6). 각 레이어는 두 서브레이어(Sub-layer)가 있습니다. 첫 번째는 multi-head self-attention(멀티헤드 셀프어텐션) 이고 두 번째는 position-wise fully connected feed-forward network 입니다. 이 때 두 서브 레이어에 잔차 연결(residual connection)을 사용한 다음, 레이어 정규화를 수행합니다. 즉, \(Sublayer Output = LayerNorm(x + Sublayer(x))\) 함수 식으로 표현할 수 있습니다. 이 때 x는 서브 레이어의 입력, \(Sublayer(x)\) 는 해당 서브레이어의 출력이고, 이후에 레이어 정규화를 진행합니다. 이러한 잔차 연결을 용이하게 하기 위해 모든 모델의 서브레이어와 임베딩 레이어는 512 차원의 output을 생상합니다.
-
Decoder : 디코더 역시 동일한 레이어의 스택으로 구성되어 있습니다. 다만 디코더에서는 인코더와 달리 세 개의 서브레이어가 있습니다. 새로 추가된 서브레이어는 인코더 스택의 아웃풋에 대한 멀티헤드 어텐션을 수행하고, 이외의 구조는 인코더와 같습니다. 이 때 디코더 스텍에서 셀프어텐션 서브레이어가 이전과 현재 위치만 참조하고, 이후의 위치를 참조하지 않도록 위치를 수정했습니다. 이 이유는 디코더가 순차적 예측(autoregressive prediction) 을 수행하기 때문입니다. 즉, 디코더는 한 번에 하나씩 다음 단어를 예측하는 방식으로 작동하며, 이전에 예측한 단어들만을 참고해서 연재 단어를 예측할 수 있어야 합니다. 다시 말하면, 각 위치가 미래 단어들을 참조하지 못하도록 해야 합니다. 이를 구현하기 위해 마스킹 기법을 사용합니다.
2.2 Attention
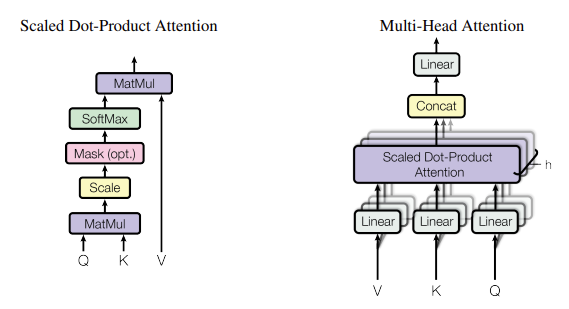 그림2 - (왼쪽) Scaled Dot-Product Attention. (오른쪽) Multi-Head Attention은 병렬로 실행되는 여러 어텐션 레이어로 구성
그림2 - (왼쪽) Scaled Dot-Product Attention. (오른쪽) Multi-Head Attention은 병렬로 실행되는 여러 어텐션 레이어로 구성어텐션 함수는 Query와 key-value 세트를 출력에 매핑하는 것으로 설명할 수 있으며, 여기서 Q, K, V는 모두 벡터입니다. 출력은 V의 가중 합(weighted sum)으로 계산되며, 각 값에 할당된 가중치는 해당 K와 Q의 호환성 함수(Compatibility function)에 의해 계산됩니다.
- Scaled Dot-Product Attention : 입력은 K와 V의 차원 \(d_{K}, d_{V}\) 로 구성됩니다. 수식은 아래와 같습니다.
Q와 K의 내적으로 관계를 판단합니다. 값이 클수록 관계가 높습니다. 하지만 극단적으로 커저버리면 softmax가 매우 작은 그래디언트를 갖는 영역으로 밀려날 것이기 때문에, $d_k$ 로 나눠줍니다.
예를 들어 설명해보겠습니다. Transformer 모델이 “I love cats”라는 문장을 이해하려 한다고 가정해봅시다. 여기서 각 단어는 다음과 같은 역할을 할 수 있습니다:
- “I”: 주어 (사람)
- “love”: 동사 (행동)
- “cats”: 목적어 (대상)
모델은 이 세 단어의 의미를 이해하면서, 각 단어가 문장에서 어떤 역할을 하는지, 그리고 서로 어떻게 연결되는지 파악해야 합니다. 이 과정에서 Attention 수식이 어떻게 적용되는지 직관적으로 설명해보겠습니다.
#### Query (Q), Key (K), Value (V)의 역할 ####
-
Query (Q): “내가 지금 집중하고 싶은 단어”에 해당합니다. 예를 들어, “love”라는 단어가 문장에서 다른 단어와 어떤 관계가 있는지 확인하기 위해 “love”가 Query가 됩니다.
-
Key (K): “문장 내 다른 단어들이 가진 정보”입니다. 각 단어가 어떤 의미를 가지고 있는지 표현하는 역할을 합니다.
-
Value (V): 최종적으로 전달할 정보의 실제 값입니다. 각 단어의 의미를 최종 출력에 반영하기 위해 사용됩니다.
이때, “love”라는 Query가 “I love cats”라는 문장의 다른 단어들(Key)에 대해 어떤 관계가 있는지를 파악하려고 합니다.
#### Query와 Key의 내적: 관계의 유사도 계산 ####
-
위에서 언급했듯이 Q와 K의 내적을 통해 벡터 간 유사도를 계산합니다.
-
이 예시에서는 “love”라는 Query와 “I”, “love”, “cats”라는 Key들 간의 유사도를 계산하게 됩니다.
-
내적 결과가 클수록 두 단어가 더 강하게 연결되어 있다고 해석할 수 있습니다. 예를 들어, “love”와 “I”는 주어와 동사의 관계를 가지고 있으므로 유사도가 높을 수 있으며, “love”와 “cats”도 동사와 목적어의 관계로 유사도가 높을 수 있습니다.
#### 스케일링과 Softmax로 가중치 계산 ####
-
내적 결과를 K의 차원에 루트를 씌운 채로 나누어 스케일링 합니다. 이는 큰 값을 줄여주는 역할을 하여 softmax가 너무 극단적인 결과를 내지 않게 합니다.
-
이 스케일링된 값을 Softmax 함수에 넣어, 각 단어가 해당 Query에 대해 얼마나 중요한지를 나타내는 가중치로 변환합니다.
-
예를 들어, “love”라는 Query에 대해 “I”와 “cats”는 더 높은 가중치를 받을 수 있고, “love” 자기 자신은 상대적으로 낮은 가중치를 받을 수도 있습니다(상황에 따라 다름).
#### 최종 출력 계산 ####
-
마지막으로, 이 가중치를 V에 곱하여 가중합을 계산합니다. 이 가중합은 “love”라는 Query가 문장에서 전체적인 문맥을 이해할 수 있도록 돕는 정보입니다.
-
즉, “love”는 “I”와 “cats”를 참조하면서 이들이 주어와 목적어라는 점을 바탕으로 자신과의 관계를 강화하여 문장에서의 역할을 학습하게 됩니다.
-
Multi-Head Attention : 저자는 $d_model$ 차원의 Q, K, V로 단일 어텐션을 사용하는 것보다, 각각의 차원에 대해 서로 다른 학습된 linear projection(고등학교 때 배우는 정사용과 유사합니다.)을 이용하여 Q, K, V 값을 h번 선형적으로 투영하는 것이 유익하다는 것을 발견합니다. 이러한 각 투영된 Q, K, V 버전에서 어텐션 함수를 병렬로 수행하여 $d_v$ 차원의 출력 값을 생성합니다. 이러한 값을 연결하고 다시 투영하여 그림 2에 나와 있는 것처럼 최종 값을 생성합니다.
예를 들어 $d_model$ 차원이 512이고, h = 8 의 병렬 어텐션 레이어면, \(d_{k} = d_{v} = d_{model}/h = 64\) 로 사용할 수 있습니다. 각 헤드의 차원이 줄어들었기 때문에 전체 계산 비용은 전체 차원에 대해 계산한 단일 어텐션과 유사합니다. 그러면 수식을 보겠습니다.
\[\text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \ldots, \text{head}_h)W^O\] \[\text{where } \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V)\]Q, K, V에 linear projection을 적용한 새로운 값들을 어텐션 함수에 적용하고 각각의 헤드를 concatation 해준 뒤, 최종 출력을 원하는 차원으로 변환하는 선형 변환 가중치와 가중 합을 진행하는 계산 과정을 거칩니다. 직관적으로 설명해보겠습니다.
-
첫 번째 어텐션 헤드는 “I”와 “love”의 주어-동사 관계에 집중할 수 있습니다.
-
두 번째 어텐션 헤드는 “love”와 “cats”의 동사-목적어 관계를 학습할 수 있습니다.
-
세 번째 어텐션 헤드는 “I”와 “cats” 간의 관계를 참조하여 전체 문장의 문맥을 이해하는 데 도움을 줄 수 있습니다.
이렇게 여러 관점에서 학습된 정보가 결합되면, 한 번에 문장을 처리할 수 있고, 모델이 문장을 더욱 풍부하게 이해하고 표현할 수 있습니다.
Position-wise Feed-Forward Networks
이 네트워크는 Self-Attention 층을 거친 각 위치의 출력을 개별적으로 처리하여 모델이 각 단어의 특징을 더 복잡하게 변환할 수 있도록 도와줍니다. 이 과정은 시퀀스 내의 각 위치에서 독립적으로 적용되므로, 인코더나 디코더가 시퀀스의 특정 위치의 정보를 더욱 복잡하고 비선형적으로 변환할 수 있습니다. 수식은 아래와 같습니다.
\[FFN(x) = \text{max}(0, xW_1 + b_1)W_2 + b_2\]x는 셀프어텐션 층의 출력입니다. x에 학습 가능한 첫 번쨰 가중치 행렬을 곱하고 바이어스를 더한 후 ReLU 활성화 ㅎ함수를 적용합니다. 이 단계에서 비선형 변환을 통한 복잡한 특징을 학습합니다. 이후 두 번째 가중치를 곱하고 바이어스를 더해 최종 출력을 얻습니다. 이 과정에서 다시 원래 모델의 차원으로 돌려 놓습니다. 이 과정은 시퀀스 내의 각 위치에서 독립적으로 적용되므로, 인코더나 디코더가 시퀀스의 특정 위치의 정보를 더욱 복잡하고 비선형적으로 변환할 수 있습니다.
Embeddings and Softmax
다른 시퀀스 변환 모델과 마찬가지로 학습된 임베딩을 사용하여 입력 토큰과 출력 토큰을 $d_model$ 차원의 벡터로 변환합니다. 일반적인 학습된 선형 변환과 소프트맥스 함수를 사용하여 디코더 출력을 예측한 다음 토큰 확률로 변환합니다.
Positional Encoding(PE)
Transformer 모델에서 위치 정보를 나타내기 위해 사용되는 메커니즘입니다. RNN과 달리 Transformer는 순차적인 순서를 따르지 않기 때문에 위치 정보를 내재적으로 알 수 없습니다. 이를 보완하기 위해 PE를 통해 각 단어의 위치 정보를 벡터에 추가하여 단어 간 순서와 거리를 모델이 인식합니다. 위치가 가까운 단어들은 비슷한 주기 값을 가지므로, 모델이 이 단어들이 서로 가깝다는 정보를 학습할 수 있고, 위치가 먼 단어들은 더 상이한 주기 값을 가지므로, 모델이 이 단어들이 떨어져 있다는 정보를 알 수 있습니다.
\[PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{\frac{2i}{d_{model}}}}\right)\] \[PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{\frac{2i}{d_{model}}}}\right)\] -
-
Why Self-Attention
위 내용을 토대로 왜! Self-Attention이 좋은지! Transformer의 장점이 뭔지! 요약하겠습니다.
-
Long-Term Dependencies
RNN은 문장의 앞부분과 뒷부분에 있는 단어 간의 관계를 학습하려면 여러 단계를 거쳐야 하므로 비효율적임 Self-Attention은 모든 단어가 다른 모든 단어와 직접 연결될 수 있음, 즉, 모든 단어 간의 종속 관계를 한 번의 어텐션으로 계산 가능
-
계산 효율성과 병렬 처리
RNN은 시퀀스를 순차적으로 처리해야 하기 때문에 병렬 처리가 어려움 Self-Attention은 병렬 처리가 가능하여 모든 단어가 동시에 서로의 관계를 계산할 수 있으며, 이는 GPU 같은 병렬 처리 하드웨어세서 더 효율적임
-
가변 길이 입력 처리
Self-Attention은 시퀀스 길이에 제한 없이 가변 길이의 입력을 처리할 수 있음 해석 가능성 어텐션 가중치(Attention Weights)를 통해 모델이 특정 단어를 예측할 때 어떤 단어에 주의를 기울였는지 확인할 수 있음
실제로 논문에서 제시한 Table1을 보면 알고리즘 복잡도를 통해 모델의 타당성을 이야기하고 있습니다. (표는 생략하겠습니다.)
-
여기까지 모델의 연구 배경, 구조, 장점 정리까지 해보았습니다. 도움이 되셨길 바랍니다.😁
Follow my github
{kind=link}