BigVGAN 이란?
by DINHO
캡스톤 진행, 시험 기간 등 여러 일정들이 겹치면서 블로그 포스팅에 소홀해지는 것 같습니다ㅠㅠ 최대한 꾸준하게 하는 것을 목표로 하고 있는데, 밀린 내용들이 많네요… 5월 중순부터는 스케줄이 넉넉해질 것 같아서 다시 열심히 해보도록 하겠습니다.
오늘은 BigVGAN(Lee, Sang-gil, et al. “Bigvgan: A universal neural vocoder with large-scale training.” arXiv preprint arXiv:2206.04658 (2022).) 논문 리뷰를 해볼까 합니다.
지난 번에 HiFiGAN 모델에 대해서 리뷰를 했는데요!! 제가 캡스톤 프로젝트를 진행하면서 HiFiGAN을 이용하게 되었는데 여러 문제점을 겪었습니다. 해결 방법을 찾아보다가 BigVGAN이라는 모델을 발견하였습니다. 그래서 이번에는 HiFiGAN의 변형 모델인 BigVGAN에 대해 리뷰를 해보겠습니다.
Problem
먼저 HiFiGAN이 가지고 있는 문제점에 대해 설명하겠습니다.
기존 HiFiGAN 파라미터 들은 더 쉬운 모델링을 위해 고주파수 세부 정보를 차단한 0~8kHz 대역의 오디오 신호만을 갖도록 설계되었습니다.
제가 현재 진행하고 있는 캡스톤 프로젝트는 “생성형 AI모델을 이용한 디지털 이명 치료제”인데, 기존의 오디오 생성형 AI(Auffusion, AudioLDM2 등)은 Vocoder로 HiFiGAN을 사용하기 때문에 이명 치료음 생성에 적합하지 않습니다.(기본적으로 인간의 가청 주파수가 22kHz까지이고, 이명 주파수 대역은 4kHz~8kHz 정도 입니다. TMNMT 방법을 사용하게 되면 측면 억제를 위해 주파수 대역에서 +-1옥타브, 1/2옥타브 대역 등을 필터링 해주게 되는데, 이 때 HiFiGAN의 문제점이 드러납니다.)
또한, 긴 시간의 음원을 생성했을 때 음원의 품질이 현저히 저하됩니다.
BigVGAN의 생성기를 Vocoder로 사용하면 위와 같은 문제를 해결할 수 있게 됩니다!!🙂🙂 이제부터 차근차근 그 이유에 대해 설명해보겠습니다.
Overview
BigVGAN은 기본적으로 HiFiGAN의 변형 모델입니다.
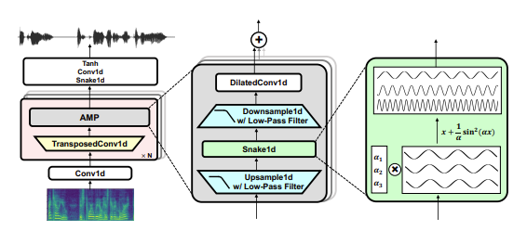
먼저 생성기에서는 기존 HiFiGAN의 생성기의 MRF 구조를 변형했습니다. 활성화 함수에 기존 LeakyReLU 대신 아래와 같은 Snake function을 사용했습니다.
\[x + sin^{2}(x)\]HiFiGAN의 판별기 종류 기억하시나요?? MPD(Multi-Period Discriminator)와 MSD(Multi-Scale Discriminator)가 있는데요. BigVGAN에서는 MSD를 사용하지 않고 Univnersal melgan의 MRD를 적용하였습니다.
간략한 개요는 이 정도 입니다. 이제 자세한 내용 이어서 이야기하겠습니다.
Introduction
이 논문에서는 생성기를 향상시키는 데 중점을 두었습니다. 주기적인 Inductive Bias를 제공하기 위해 snake function을 사용했습니다. 또한 앨리어싱 방지를 위해 Low-Pass Filter를 사용했습니다.
 이미지 출처: BigVGAN
이미지 출처: BigVGAN
Method
계속 이야기 했듯이 HiFi-GAN을 기본 구조로 선택했습니다. universal melgan에 쓰인 MRD와 자체 개발 기술 AMP를 HiFiGAN에 추가하고 적용하는 방식입니다. 궁극적인 목적 역시 HiFiGAN과 유사합니다.
- Periodic Inductive Bias
BigVGAN에서는 주기적 Inductive Bias에 초점을 두었습니다. Inductive Bias는 본 적 없는 입력에 대한 출력을 예측하기 위해 만드는 가정 세트입니다.
TTS에서 오디오 파형은 높은 주기성을 보이며, 푸리에 분석에 따르면 모든 주기 신호는 특정 조건(Dirichelt Conditions)에서 더 간단한 사인파 신호들로 분해될 수 있습니다. 기존 HiFIGAN에서 사용했던 Leaky ReLU는 비선형성에 유용하지만, Pereiodic Bias 내장하지 않아서 훈련 데이터에서 벗어난 오디오를 예측하는 데부적합 합니다.이를 해결하기 위해 Snake 함수 를 도입합니다.
\[x + {1/α}sin^{2}(αx)\]여기서 α는 신호의 주기적 구성 요소와 주파수를 결정하는 학습 가능한 매개변수입니다. 이 함수의 도입을 통해 원하는 주기적 Unductive Bias를 추가하여 오디오의 주기적 요소를 더잘 학습하고 생성합니다.
Result
깨끗한 환경에서기록된 이전의 연구와 달리 다양한 녹음 환경의 subset을 이용합니다. 기존의 STFT 파라미터들은 더 쉬운모델링을 위해 고주파수 세부 정보를 차단한 0~8kHz를 갖도록 설계되었지만 이 논문에서는 주파수 범위 0~12kHz와 100band 멜-스펙트로그램을 사용하여 모든 모델을 훈련하였습니다.
 이미지 출처: BigVGAN
이미지 출처: BigVGAN
표 1에서는 오디오 합성 속도를 이야기 합니다. 기족 HiFiGAN은 실시간보다 93.75배 빠른 속도를 보이고 있고, BigVGAN은 그보다 느린 44.72배의 속도를 보이고 있습니다. 논문에서는 자세한 설명을 하지 않았지만, 제 생각에 snake 함수가 Leaky ReLU보다 복잡하기 때문이지 않을까 싶습니다. 하지만 논문에서 중요하게 생각하는 평가지표는 표2입니다.
 이미지 출처: BigVGAN
이미지 출처: BigVGAN
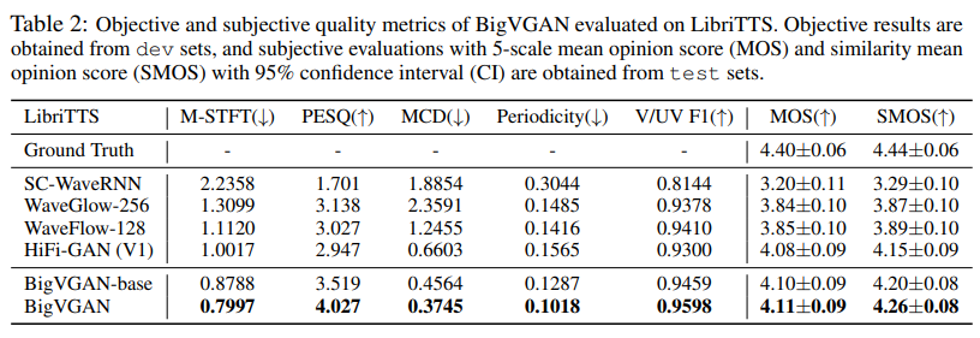
표 2에는 객관적 지표와 주관적 지표가 다 나와 있습니다 표를 보면 아시겠지만 객관적 평가지표와 주관적 평가지표 두 부분 모두 BigVGAN이 우수하다고 보여줍니다. 결론적으로 속도는 느리지만 성능은 좋아졌습니다.
여기까지 BigVGAN 리뷰를 마치겠습니다. 학기 중에는 꾸준한 블로그 포스팅이 힘드네요..ㅠ 그래도 최대한 열심히 꾸준하게 포스팅해보도록 하겠습니다.
Follow my github
{kind=link}