Live Music Models 리뷰
by DINHO
안녕하세요! 오늘은 Google DeepMind의 Lyria Team에서 발표한 “Live Music Models” 논문에 대해 리뷰를 해보겠습니다. 이 논문은 NeurIPS 2025 Creative AI Track에 게재된 논문으로, 실시간 라이브 음악 생성이라는 새로운 패러다임을 제시합니다.
Introduction, Method, Experiments, Controllable Generation, Conclusion 순서로 이야기하겠습니다.
Introduction
음악의 두 가지 형태
논문은 음악이 두 가지 상보적(complementary) 형태로 존재한다는 점에서 출발합니다.
-
정적인 녹음된 작품 (‘명사로서의 음악’, music as a noun)
-
실시간으로 집단적으로 경험되는 라이브 공연 (‘동사로서의 음악’, music as a verb)
라이브 음악은 창작적 몰입(creative flow), 체화된 표현(embodied expression), 사회적 연결(social connection)이라는 인간의 근본적 경험과 깊이 연결되어 있습니다. 그럼에도 불구하고 기존 생성 AI 시스템은 오프라인, 턴 기반 생성에 압도적으로 치우쳐 있었습니다.
오프라인 vs 라이브 생성
오프라인 세팅에서는 사용자가 제어 정보를 입력하고, L초(오프라인 지연시간)를 기다린 뒤, T초의 오디오를 받는 방식입니다. 반면 라이브 세팅에서는 사용자가 연속적으로 제어 정보를 입력하면서, T초의 상호작용으로부터 T초의 끊기지 않는 오디오 스트림을 받으며, 제어 입력과 오디오 출력 사이에 D초의 지연이 존재합니다.
논문에서는 사용자를 지속적인 인지-행동 루프에 배치하면 더 능동적인 창작을 촉진하고, 더 높은 대역폭의 상호작용을 만들며, 개인화된 표현을 장려하고, 결과물만큼이나 과정을 강조하게 된다고 주장합니다.
Live Music Model의 정의
논문의 핵심 기여 중 하나는 live music model을 명확하게 정의한 것입니다. 다음 세 가지 속성을 모두 갖춘 모델만이 라이브 음악 모델이라고 규정합니다.
-
실시간 생성: 처리량 RTF(Real Time Factor) ≥ 1× (RTF = T/L, 값이 높을수록 빠름)
-
인과적 스트리밍: 사용자 제어 입력과 과거 오디오 출력 모두의 함수로서 연속적으로 오디오를 생성
-
반응형 제어: 지연 D가 낮아 라이브 상호작용을 용이하게 함
기존 일부 오프라인 모델도 RTF ≥ 1×을 달성하지만, 인과적 스트리밍이나 반응형 제어가 부족하여 라이브 공연에는 적합하지 않다는 것이 저자들의 주장입니다.
오픈 웨이트 모델의 중요성
저자들은 온디바이스 모델이 라이브 생성 음악에 특히 적합한 이유를 네 가지로 제시합니다.
-
네트워크 요청을 제거하여 더 낮은 지연시간
-
실제 환경에서의 사용을 용이하게 하는 높은 신뢰성
-
프라이버시 보장
-
아티스트에 의한 커스터마이징
제안하는 시스템
이러한 배경 하에 저자들은 두 가지 시스템을 소개합니다.
-
Magenta RealTime (Magenta RT): 오픈 웨이트, 온디바이스 모델
-
Lyria RealTime (Lyria RT): API 기반, 클라우드 모델
두 모델 모두 codec language modeling 프레임워크를 핵심으로 사용하며, SpectroStream 오디오 코덱에서 생성된 토큰을 언어 모델로 모델링하는 구조입니다.
특히 Magenta RT는 750M 파라미터로 Stable Audio Open(1.2B) 대비 38%, MusicGen Large(3.3B) 대비 77% 적은 파라미터를 사용하면서도 음악 품질의 자동 메트릭에서 이들을 능가합니다.
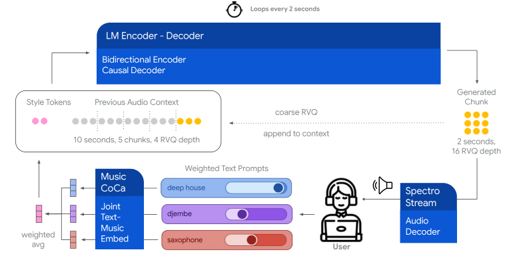
[그림 1] Magenta RealTime Architecture
Method
Magenta RT는 codec language model 기반으로, acoustic style conditioning에 따라 실시간으로 고충실도 스테레오 오디오를 생성하도록 설계되었습니다. (1) SpectroStream (오디오 코덱), (2) MusicCoCa (스타일 임베딩), (3) Encoder-Decoder LM (언어 모델)의 3단계 파이프라인으로 구성됩니다.
Audio Tokenization via SpectroStream
이전에 MusicGen 포스팅에서 EnCodec과 RVQ에 대해 다룬 적이 있는데요, 이 논문에서도 비슷한 개념이 핵심적으로 사용됩니다.
Codec language modeling은 이산 오디오 코덱을 사용하여 오디오 데이터를 언어와 유사한 토큰으로 변환합니다. 코덱은 인코더와 디코더의 함수 쌍으로, 최소한의 인지 가능한 왜곡으로 오디오를 압축 공간으로 변환하고 복원합니다.
이 논문에서는 SpectroStream이라는 코덱을 채택합니다. 사양은 다음과 같습니다.
-
샘플링 레이트: fs = 48kHz (풀밴드)
-
RVQ 기반: Residual Vector Quantization
-
전체 대역폭: 16kbps (fk = 25Hz, dc = 64, Vc = 1024)
여기서 중요한 점은 라이브 스트리밍을 위한 대역폭 축소입니다. 전체 64개 RVQ 레벨 중 처음 16개만 생성하여 대역폭을 4kbps로 줄이며, 초당 400개 토큰의 라이브 처리량 목표를 설정합니다. RVQ의 계층적 구조 덕분에, 낮은 양자화 레벨이 가장 중요한 음향 정보를 포착하기 때문에 이러한 축소가 가능합니다.
Style Embeddings via MusicCoCa
MusicCoCa는 오디오와 텍스트를 공유 임베딩 공간에 매핑하여, 사용자가 텍스트 또는 오디오 프롬프트로 음악 스타일을 제어할 수 있게 합니다. MuLan과 CoCa를 기반으로 한 contrastive captioner 구조입니다.
오디오 임베딩 타워 (MA)는 12-layer ViT로, 10초 16kHz 오디오의 log-mel spectrogram(128채널, 길이 992)을 입력받고, 패치 크기 16×16으로 처리합니다. 텍스트 임베딩 타워 (MT)는 12-layer Transformer로, 최대 시퀀스 길이 128 토큰을 처리합니다.
두 타워 모두 attention pooling을 통해 단일 768차원 임베딩으로 축소됩니다. 이 임베딩은 codebook 크기 1024인 12개의 이산 토큰으로 양자화되어 LM 인코더의 조건 신호로 사용됩니다.
학습은 Adafactor 옵티마이저, 학습률 1×10⁻⁴, 배치 크기 1024, 총 16,000 스텝으로 진행됩니다.
Modeling Framework
Magenta RT는 AudioLM/MusicLM의 구조를 부분적으로 따르되, 라이브 생성을 위해 두 가지 핵심 변경을 제안합니다.
-
다수의 LM의 계층적 캐스케이드를 단일 LM으로 대체
-
무한 스트리밍 생성을 가능하게 하는 청크 기반 자기회귀 접근법 제안
Chunk-based Autoregression
이 부분이 라이브 생성의 핵심 기술입니다. 모델은 학습 시 유한한 길이의 시퀀스만 보지만, 추론 시에는 무한한 길이를 생성해야 합니다. 이 길이 불일치 문제를 해결하기 위해, 기존 연구에서는 슬라이딩 어텐션 윈도우와 상대적 위치 인코딩을 사용했지만 본 논문에서는 다른 접근을 취합니다.
C = 2초 길이의 청크 단위로 동작하며, 마르코프 가정 하에서 H = 5개의 이전 청크(10초의 히스토리)를 기반으로 각 청크를 예측합니다. 이를 비유하면 “즉흥 이야기꾼”에 가깝습니다.
-
2초짜리 청크를 한 번에 하나씩 생성
-
직전 10초의 내용만 기억 (마르코프 가정)
-
그보다 오래된 내용은 잊어버림
-
매번 사용자로부터 새로운 지시를 받을 수 있음
이 접근의 장점은 오류 누적 감소 (10초 이전 실수를 잊으므로 자연스럽게 리셋), 무상태(stateless) 추론 (KV 캐시 유지 불필요, 배포 단순화), 제어 유연성 (청크 간 컨디셔닝 업데이트 가능) 등입니다.
Coarse Context
RTF ≥ 1×을 달성하기 위해, 오디오 컨텍스트에 전체 RVQ depth 대신 coarse한 표현을 사용합니다. RVQ의 계층적 구조에서 낮은 양자화 레벨이 가장 두드러진 음향 정보를 포착하기 때문에, 히스토리에는 처음 4개 RVQ 토큰만으로도 충분합니다.
| 구분 | RVQ 깊이 | 역할 |
|---|---|---|
| 타겟 청크 (생성할 2초) | 16 levels | 높은 충실도 필요 |
| 컨텍스트 (이전 10초) | 4 levels | 전체적 음향 파악 |
컨텍스트 토큰을 4분의 1로 줄이면 Transformer 인코더의 연산량이 대폭 감소합니다. 최종 모델링 목표는 다음과 같습니다.
\[P_\theta(\text{Chunk}_i \mid \text{Coarse}_{i-H:i}, c_i)\]인코더 입력: 총 1,012 토큰 (1,000 오디오 + 12 스타일)
Encoder-Decoder Language Model
T5X 프레임워크로 학습된 encoder-decoder Transformer LM이며, T5 Base(220M)와 Large(770M) 설정으로 공개됩니다.
인코더(양방향)는 음향 히스토리와 스타일 제어를 중간 표현으로 처리합니다. 디코더는 두 개의 연결된 Transformer 모듈로 구성됩니다.
-
시간적(temporal) 모듈: 음향 프레임을 처리하여 시간적 컨텍스트를 구성. 각 프레임 내의 RVQ 토큰들이 임베딩되고 집계되어 단일 프레임 수준 임베딩을 산출
-
깊이(depth) 모듈: 이전 시간적 컨텍스트에 조건화하여 RVQ 인덱스의 자기회귀 예측을 수행
이 구조를 통해 H100 GPU에서 T5 Large 설정으로 RTF = 1.8을 달성합니다.
MusicGen에서는 Delay Pattern으로 코드북을 처리했었는데, Magenta RT에서는 temporal + depth의 2단계 디코더 구조로 효율성을 극대화한 점이 차별점입니다.
Experiments
실험 셋업
학습에는 약 190,000시간의 주로 기악 스톡 음악 데이터셋을 사용합니다. 각 학습 예시는 12초 오디오 클립(10초 컨텍스트 + 2초 타겟)으로 구성됩니다. 총 186만 스텝, 배치 크기 512, Adafactor 옵티마이저로 학습했으며, TPU-v6e(Trillium) 하드웨어를 사용합니다.
샘플링에는 classifier-free guidance(CFG)를 사용하며, temperature 1.3, top-K 40, CFG weight 5.0으로 설정합니다.
오디오 품질 및 텍스트 준수 평가
Song Describer Dataset에서 47초 고정 길이로 비교한 결과입니다.
| 모델 | Live | Sample rate | Params | FD_openl3 ↓ | KL_passt ↓ | CLAP_score ↑ |
|---|---|---|---|---|---|---|
| Magenta RT | ✓ | 48 kHz | 760M | 72.14 | 0.47 | 0.35 |
| Stable Audio Open | ✗ | 44.1 kHz | 1.1B | 96.51 | 0.55 | 0.41 |
| MusicGen-stereo-large | ✗ | 32 kHz | 3.3B | 190.47 | 0.52 | 0.31 |
Magenta RT가 FD_openl3와 KL_passt에서 가장 좋은 점수를 보여, 생성된 오디오가 실제 오디오와 유사하다는 것을 나타냅니다. CLAPscore는 Stable Audio Open이 약간 더 높은데, 이는 Stable Audio Open이 학습 시 CLAP 임베딩을 사용하기 때문일 수 있습니다.
또한, 이 논문 작성 시점에서 Magenta RT는 Music Arena 리더보드에서 오픈 웨이트 모델 1위로 랭크되어 있다고 합니다.
음악 전환(Transition) 평가
라이브 음악 모델만의 고유한 능력을 평가하기 위해, 텍스트 프롬프트 쌍 간의 전환 실험을 수행합니다. 60초에 걸쳐 MusicCoCa 텍스트 임베딩을 선형 보간하고, 출력 오디오 임베딩과 조건 임베딩 간의 코사인 유사도를 측정합니다. 결과적으로 Magenta RT는 전환 과정에서 타겟 임베딩과 높은 유사도를 유지하면서 스타일을 부드럽게 전환합니다.
Controllable Generation
Style Conditioning via Text and Audio
추론 시, N개의 제어 프롬프트(텍스트 또는 오디오)의 MusicCoCa 임베딩을 가중 평균하여 타겟 컨디셔닝 벡터를 만듭니다.
\[\mathbf{c} = \sum_{i=1}^{N} w_i M(\mathbf{c}_i) / \sum_i w_i\]MusicCoCa 임베딩을 사용하는 핵심 장점은 임베딩 산술(embedding arithmetic)로 스타일을 블렌딩할 수 있다는 것입니다. 예를 들어, embed(“techno”)와 embed(“flute”)의 가중합은 embed(“techno flute”)의 좋은 근사치를 제공하며, 각 개념의 상대적 영향력도 가중치로 제어할 수 있습니다.
또한 오디오 프롬프트를 사용하면 텍스트로 표현하기 어려운 특정 음악 스타일이나 악기를 더 직접적으로 제어할 수 있습니다. 오디오 프롬프트는 학습 세팅(타겟 오디오에서 스타일 추출)에 더 가깝기 때문에 텍스트 프롬프트보다 효과적일 것으로 기대됩니다.
전반적으로, 이 컨디셔닝은 장르, 스타일, 악기 구성, 분위기 같은 고수준 특성에 대한 제어를 제공합니다.
Audio Injection
Audio Injection은 사용자가 라이브 오디오 스트림으로 생성을 지속적으로 조종하는 메커니즘입니다.
각 생성 단계에서, 사용자의 입력 오디오를 모델의 출력과 혼합하고, 결과 혼합물을 토큰화하여 다음 생성의 컨텍스트로 입력합니다. 중요한 점은 사용자 오디오는 절대 직접 재생되지 않는다는 것입니다. 모델은 사용자 오디오를 포함하는 과거 컨텍스트의 연속을 예측하는 것이며, 상황에 따라 사용자 오디오를 반복하거나, 변형하거나, 그 특징에 영향만 받을 수 있습니다.
사용자 오디오의 영향력 조절에는 Classifier-Free Guidance(CFG)를 사용합니다.
\[(1 + w) \cdot \text{Logits}_{\text{pos}} - w \cdot \text{Logits}_{\text{neg}}\]양성 예시(사용자 입력 혼합)와 음성 예시(모델 출력만)를 모두 추론하여, 가중치 w로 영향력을 제어합니다.
레이턴시 문제를 해결하기 위해 “Free” 모드와 “Looper” 모드 두 가지가 제안됩니다.
-
Free 모드: 사용자 입력을 원래 타이밍에 맞춰 혼합. 직관적이지만 컨텍스트 끝부분에서 사용자 영향이 끊기는 문제가 있음
-
Looper 모드: 고정 템포의 반복 구조를 가정하고 이전 루프의 오디오를 현재 컨텍스트에 혼합. 영향력이 강하지만 한 루프만큼 지연되고 템포 지정이 필요
Conclusion
이 논문에서는 라이브 음악 모델이라는 새로운 클래스의 생성 시스템을 소개했습니다. 인터랙티브하고 human-in-the-loop인 공연이라는 새로운 패러다임을 제시하며, 최종 결과물보다 창작 과정(creative process)을 강조합니다.
향후 연구 방향으로는 두 가지를 제시합니다.
-
초저지연 제어: 현재 2초 이상의 지연을 대폭 줄여 실시간 악기나 이펙터처럼 동작하게 하는 것
-
멀티 스템 학습: 모델이 음악적 파트너로서 사용자와 함께 잼을 하고 동적인 라이브 반주를 제공하는 것
한계점
-
2초 청크 단위 동작으로 인해 사용자 입력이 출력에 영향을 미치기까지 2초 이상 소요
-
최대 10초의 오디오 컨텍스트 윈도우로 인해 장기적인 곡 구조(verse-chorus 등)를 자동으로 만들기 어려움
마무리
이 논문을 읽으면서 몇 가지 인상적인 점이 있었습니다.
첫째, “live music model”이라는 개념을 세 가지 속성으로 명확히 정의한 것이 깔끔했습니다. 기존에도 RTF ≥ 1×을 달성하는 모델은 있었지만, 인과적 스트리밍과 반응형 제어까지 포함하여 라이브 음악에 필요한 조건을 체계적으로 정리한 것은 이 논문이 처음입니다.
둘째, Chunk-based Autoregression과 Coarse Context의 조합이 영리했습니다. 2초 청크 단위 + 마르코프 가정으로 무한 스트리밍 문제를 해결하면서, 컨텍스트에 coarse RVQ만 사용하여 연산량을 크게 줄인 것은 실용적인 해법이라고 느꼈습니다.
셋째, 750M 파라미터로 MusicGen Large(3.3B)를 능가한다는 것은 아키텍처 설계와 학습 전략이 단순한 스케일링보다 중요할 수 있다는 점을 보여주는 좋은 사례인 것 같습니다.
제가 진행하고 있는 tinnicare 프로젝트 관점에서도, 실시간 치료 사운드 스트리밍에 chunk-based autoregression 아이디어를 활용할 수 있을 것 같고, 스타일 임베딩 블렌딩으로 환자별 맞춤 치료 사운드를 생성하는 방향도 흥미로운 연구 주제가 될 수 있을 것 같습니다.
여기까지 Live Music Models 논문 리뷰를 마치겠습니다! 감사합니다.
Follow my github
{kind=link}