SpeechLM이란?
by DINHO
오랜만에 인사드립니다! 연말 연초에 논문 Rebuttal 쓰랴 과제 제안서 작성하랴 기초전자및회로실험1 조교하랴 바쁘디 바쁜 시간을 보냈습니다.
석사 3학기인 만큼 포트폴리오 정리도 하고, 앞으로의 진로 고민도 하게 되는 요즘입니다.
오늘은 오랜만에 논문 리뷰를 하려 합니다. 오늘 소개드릴 논문은 “Recent Advances in Speech Language Models: A Survey (2025)” Speech LM에 대한 서베이 논문입니다.
Introduction
LLM은 텍스트 기반 태스크에서 뛰어난 성능을 보입니다. 그러나 인간의 자연스러운 소통은 음성에 기반을 둡니다. 이를 해결하기 위한 가장 직관적인 접근 방식이 ASR(Auto Speech Recognization) + LLM + TTS 파이프라인입니다.

그러나 이러한 파이프라인은 근본적인 문제가 존재합니다.
Information Loss
음성 신호에는 의미론적(Semantic) 정보 외에도 운율, 음색, 감정 등 준언어적(Paralinguistic) 정보가 담겨 있습니다. 텍스트 전용 LLM을 중간에 두는 순간 이 준언어적 정보는 완전히 소실됩니다.
Significant Latency
순차적으로 동작하는 구조에서 각 모듈 내부에도 복잡한 처리가 존재하여 지연이 누적됩니다.
Cumulative Error
ASR에서 발생한 transcription 오류가 LLM 입렵 품질에 영향을 미치고 다시 TTS 품질 저하로 이어지는 오류 누적이 발생합니다.
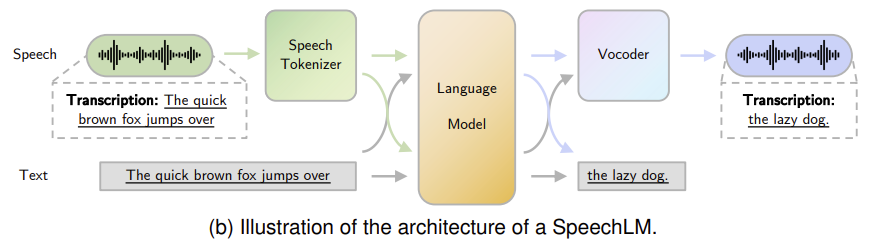
이러한 문제점들을 해결하기 위해 음성 토큰을 직접 모델링하고(준언어적 정보 보존), 단일 통합 아키텍처를 사용하며(지연 감소), 음성 인코딩과 언어 모델링의 통합 학습을 설계합니다(오류 누적 차단).
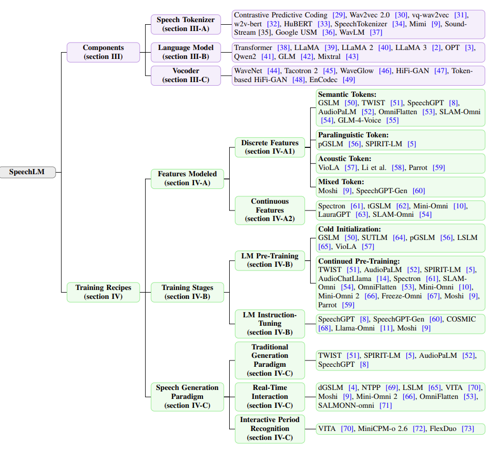
Components in SpeechLM
핵심 구성으로 speech tokenizer, language model, vocoder로 구성됩니다. 언어 모델의 입출력이 토큰 형태이기 때문에 음성 파형을 처리하기 위한 변환 모듈이 앞뒤로 필요합니다.
Speech Tokenizer
토크나이저는 연속적인 음성 파형을 discrete/continuous 토큰으로 변환합니다.
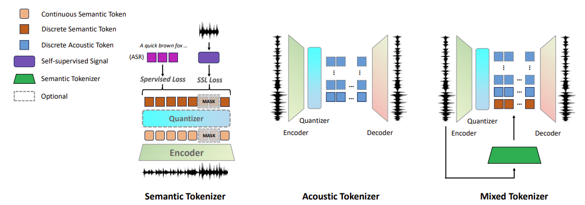
-
Semantic Understanding Tokenizer
-
의미론적 정보 포착에 초점을 맞춘 토크나이저
-
대표적으로 HuBERT가 있으며, k-means 클러스터링 기반의 마스킹 예측 방식으로 동작
-
-
Acoustic Generation Tokenizer
-
고품질 음성 파형 생성을 위한 음향적 특성 포착에 초점
-
대표적으로 Encodec이 있으며, Encoder -> RVQ -> Decoder 구조
-
-
Mixed Objective Tokenizer
-
의미론적 이해와 음향적 생성을 동시에 균형 있게 포착하는 것이 목표
-
대표 모델은 SpeechTokenizer로, HuBERT의 의미 정보를 RVQ의 첫 번째 레이어에 증류(distill)하는 방식
-
두 장점을 통합하였으며, 아직 초기 단계
-
Language Model
SpeechLM의 언어모델은 기본적으로 TextLM의 아키텍처를 그대로 차용합니다. 변경점은 텍스트 임베딩 행렬을 음성 임베딩 행렬로 교체합니다. 음성과 텍스트를 동시에 모델링 하기 위해 어휘를 확장하는 방식을 주로 사용합니다.
Vocoder
언어모델이 생성한 토큰(혹은 중간표현)을 다시 음성 파형으로 변환하는 역할입니다. GAN 기반 Vocoder가 가장 널리 사용되며, 대표적으로 HiFi-GAN이 있습니다.
Training Recipes
그렇다면 학습은 어떻게 진행될까요? Features Modeled, Training Stages, Speech Generation Paradigm 세 가지 축으로 분류합니다. 각각 모델링 되는 특징의 유형, 각 단계에서 사용되는 다양한 학습 단계 및 기법, 음성 생성 패러다임을 의미합니다.
Features Modeled
-
Discrete Features
이산 특징(이산 토큰)은 음성신호를 구별 가능하고 셀 수 있는 단위 또는 토큰으로 양자화된 표현입니다. 이 특징들은 텍스트 토큰과 동일한 방식으로 모델링 될 수 있어서 가장 널리 쓰입니다.
Semantic
-
대부분의 SpeechLM은 의미 정보가 음성 소통에서 가장 중요한 역할을 하기 때문에 의미 토큰만을 사용하여 음성을 표현
-
최초의 SpeechLM인 GSLM은 CPC, wav2vec 2.0, HuBERT 세 가지 토크나이저를 비교
-
HuBERT가 음성 재합성 및 음성 생성 등 다양한 태스크에서 가장 우수한 성능을 보임
-
의미 토큰만으로 생성된 음성은 운율, 다양한 음높이나 음색 등 표현적 정보가 부족
Paralinguistic Token
-
Semantic Token의 한계를 보완하기 위해 운율, 감정 등 준언어적 정보를 추가
-
pGSLM은 HuBERT 의미 토큰을 보완하기 위해 기본 주파수(F0)와 단위 지속 시간을 운율 특징으로 활용
-
의미 토큰, 음높이(F0), 단위 지속 시간을 별도로 예측하는 멀티스트림 트랜스포머 언어 모델을 학습
Acoustic Token
-
고품질 음성 재합성에 초점을 둔 코덱 토큰
-
고품질 음성 재합성을 위한 핵심 음향 특성을 포착하는 것을 목표
-
일부 연구에서는 코덱 토큰을 언어 모델에서 직접 모델링하며, 이를 흔히 Codec Language Model(CodecLM)이라 부름
각 토크나이저의 장단점이 뚜렷하기 때문이 이러한 장단점을 통합한 Mixed Tokenizer을 사용하고, 이에 대한 연구가 진행 중입니다.
-
-
Continuous Features
이산 특징과 달리 양자화되지 않은 실숫값으로 연속적인 스케일에 존재하는 음성 신호 표현입니다. 대표적으로 멜-스펙트로그램 같은 스펙트럼 표현이나 신경망에서 추출된 잠재 표현이 포함됩니다. 텍스트 기반 모델이 이산 단위를 처리하도록 설계되어 있기 때문에, 언어 모델의 파이프라인을 수정 하는 경우가 많습니다.
Training Stages
Pre-Training
일부 모델은 사전 학습 단계에서 파라미터를 무작위로 초기화하는 Cold Initialization 방식을 사용하지만, Cold Initialization보다 효율적인 방법으로, 기존 TextLM의 가중치에서 시작합니다.
텍스트 사전 학습된 언어 모델에서 시작하면 수렴 속도를 높이고 음성 이해 능력을 향상시킨다는 보고가 있습니다. 반대로 이미지 사전 학습 체크포인트에서 시작하면 콜드 초기화보다 오히려 성능이 낮다는 점이 발견된 연구가 있습니다.
이 결과는 텍스트와 음성 간의 언어적 공유 지식이 음성 학습에 실질적으로 도움이 됨을 시사하며, 이미지는 언어적 구조를 공유하지 않기 때문에 오히려 방해합니다.
Instruction-Tuning
사전 학습된 모델이 다양한 태스크 지시를 따를 수 있도록 파인튜닝하는 단계입니다.
Post-Alignment
학습의 마지막 단계로, 인간 선호도에 맞게 모델 출력을 정렬합니다.
Speech Generation Paradigm
Traditional Generation Paradigm
입력 시퀀스를 받아 완전한 응답을 생성하는 기본 방식입니다. 이 방식은 자연스러운 음성 상호작용의 흐름을 반영하지 못합니다.
Real-Time Interaction
인간 대화처럼 인터럽션, 동시 발화 등을 처리하는 방향입니다. 다음 프론티어는 풀-듀플렉스 모델링으로, SpeechLM이 동시 양방향 통신을 지원할 수 있도록 합니다.
Interactive Period Recognition (IPR)
모델이 언제 응답하고 언제 침묵해야 하는지를 판단하는 능력입니다.
Challenges & Future Directions
-
컴포넌트 선택에 대한 이해 부족
-
음성 토크나이저, 언어 모델, 보코더 등 핵심 컴포넌트를 포괄하며, 각각 다양한 옵션을 제공
-
주로 음성 토크나이저에 초점을 맞추고 있으며 비교의 범위와 깊이가 제한적인 경향
-
결과적으로 서로 다른 컴포넌트 선택의 장단점에 대한 이해에 상당한 공백
-
-
End-to-End 학습의 미완성
-
텍스트 신호 없이 직접 음성을 생성할 수 있음에도 불구하고, 일부 연구에서는 세 가지 컴포넌트를 별도로 학습
-
이러한 분리된 최적화는 모델의 전반적인 잠재력을 저해할 수 있음
-
보코더에서 토크나이저의까지 그래디언트를 역전파 하는 end-to-end 방식으로 학습할 수 있는지 조사해볼 가치가 있음
-
-
실시간 음성 생성의 지연 문제
- 가장 널리 채택된 접근 방식들은 입력과 출력 음성 생성 사이에 여전히 눈에 띄는 지연을 발생
-
Safety 문제
- SpeechLM의 안전성 문제에 대한 주요 우려 사항은 독성과 프라이버시를 포함
-
저자원 언어 처리
-
저자원 언어는 광범위한 텍스트 데이터가 부족하여 TextLM이 효율적으로 모델링하기 어려운 언어
-
SpeechLM은 음성 데이터를 직접 모델링하기 때문에 TextLM에 비해 저자원 언어를 더 효과적으로 처리할 수 있음
-
음성 데이터는 텍스트 데이터보다 훨씬 더 많이 존재하는 경우가 많기 때문
-
논문 내용은 여기까지입니다. 요즘 멀티모달이 대세라 VisonLM, AudioLM, SpeechLM 등 많은 모델들이 나오고 있는데, 그 중 이 논문이 SpeechLM을 가장 잘 설명하는 것 같습니다.
여기서 포스팅 마무리하겠습니다.
Follow my github
{kind=link}