A generic non-invasive neuromotor interface for human-computer interaction 리뷰
by DINHO
오늘도 너무 오랜만에 왔습니다. 꾸준함이 중요하다 생각하는데, 스스로 그러지 못 해서 반성하게 되는 요즈음 입니다. 핑계를 대보자면 논문 쓰랴, 국가 과제 프로젝트 실적 채우랴, 교수님이 시키신 일 하랴 블로그는 뒷전으로 두게 되네요… 24년엔 많은 포스팅을 했는데, 25년에는 그러지 못 한 것 같아 많이 아쉽습니다.
오늘은 국가 과제 연구를 하면서 교수님께서 시키신 일을 하다 보니 읽게 된 논문을 리뷰해보자 합니다. 오늘 리뷰는 전체를 리뷰하진 않고, 제가 프로젝트 하면서 필요한 부분만 정리를 해서, 그 부분만 리뷰해보도록 하겠습니다.
오늘 논문은 meta에서 발표한 따끈따끈한 논문 “A generic non-invasive neuromotor interface for human-computer interaction”(2025) 을 리뷰해보겠습니다. 이 논문은 sEMG를 통해 손글씨를 쓸 때 신경 신호를 이해하는 논문이라 생각하시고 아래 내용을 읽어주시면 이해가 될 것 같습니다.
먼저 제가 참여하고 있는 국가연구 과제에서는 절단 환자의 근전도 신호 추출 및 학습을 하는데요, 그에 필요한 내용을 중점적으로 공부해보았습니다.
Discrete-gesture time alignment
실험에서 제스처 수행 시점은 지시된 시간만 기록되어 실제 sEMG와 라벨간 정확한 시간 정렬이 안 됩니다. 따라서 모델이 제스처 수행 시점을 정확히 추론하기 어려움을 겪습니다.
또한, 참가자의 반응 시간 차이로 인해 프롬프트 시간과 실제 제스처 실행 시간이 일치하지 않습니다.
따라서 MPF(Multivariate Power Frequency) 기반 생성 모델을 이용해 신호를 가장 잘 설명하는 제스처 발생 시점들을 탐색하는 방식 제안합니다.
문제의 본질은 아래와 같습니다.
프롬프트 시간: "3초에 검지 핀치하세요“
3초 실제 수행 시간: 반응 지연으로 3.2초에 실행 이 0.2초 차이가 모델 학습을 망침
-
1단계 - 프롬프트 시간(3초)을 중심으로 EMG 신호를 잘라내서 평균을 구함
검지 핀치가 3초에 일어났다고 가정 → 2.9~3.1초 구간의 EMG 패턴들을 모아서 평균 → 이게 φ검지핀치(t) 템플릿
-
2단계 - 실제 시간 찾기
-
관측된 EMG 신호 x(t)는 템플릿들이 시간 이동(shift)된 것의 합
-
t_k를 조정하면서 템플릿을 좌우로 움직여 봄
-
가장 잘 맞는 위치를 찾으면 그게 실제 제스처 시간
-
-
3단계 - 템플릿을 이리저리 움직여서 실제 신호와 가장 비슷해지는 위치를 찾기
-
프롬프트: [검지핀치 1초] → [엄지탭 2초] → [중지핀치 3초]
-
실제신호: 겹쳐진 EMG 패턴들 → 어디서 어디까지가 각 제스처인지 불명확
-
생성 모델 해결책: 각 제스처의 템플릿 φ를 갖고 있음
-
이 템플릿들을 시간축에서 움직여가며 조합 조합 결과가 실제 관측 신호와 가장 비슷해지는 tk 조합을 찾음
x(t): MPF features (384차원)
ϕk(t): 제스처 인덱스 k의 프로토타입 시공간 파형
t_k : 이벤트가 발생한 시간
n(t): 노이즈
-
-
논문에서는 E단계와 M단계를 구분합니다. 동시에 최적화 하면 비선형 문제 계산 복잡도가 폭발적으로 증가하기 때문에 단계를 나눕니다.
-
E단계(템플릿 찾기): t_k 고정 → φ_k는 선형 문제 (쉬움)
-
M단계(시간 찾기): φ_k 고정 → t_k는 탐색 문제 (beam search로 해결)
-
Conformer
이제는 긴 시간 의존성을 어떻게 처리하는지에 대해 이야기해보겠습니다. 연구진은 2020년 Google이 음성 인식을 위해 개발한 모델인 Conformer를 사용합니다. Conformer는 self-attention과 Convolution을 결합한 구조입니다.
Conformer를 채택한 이유는 긴 시간적 의존성 처리와, 지역적 패턴 인식 두 마리 토끼를 다 잡기 위해서입니다.
-
긴 시간적 의존성 처리
- 손글씨는 문자 → 단어 → 문장의 긴 시퀀스, Self-attention이 장거리 의존성을 효과적으로 포착
-
지역적 패턴 인식
-
Convolution이 인접한 EMG 패턴의 지역적 특징 추출
-
개별 문자의 stroke 패턴 인식
-
저자들은 스트리밍 환경도 가능하도록 Conformer 구조를 변경합니다. 또한 Caual masking으로 실시간 처리를 하고, 미래 정보 없이 현재까지의 정보만으로 디코딩합니다.
스트리밍을 위해서 구조를 수정합니다. Attention 윈도우를 제한하고(Layer 1-10: 16 timesteps window / Layer 11-15: 8 timesteps window), Strided Convolution으로 다운 샘플링을 진행합니다(Layer 5: stride 2 (다운샘플링) / Layer 10: stride 2 (추가 다운샘플링)).
마지막으로 연구진은 CTC(Connectionist Temporal Classification) Loss와 결합합니다.
Conformer가 EMG Handwriting에 적합한 이유를 요약하자면 아래와 같습니다.
-
다중 스케일 특징 추출
-
Convolution: 짧은 문자
-
stroke Attention: 긴 단어/문장 패턴
-
-
시간적 정렬 불필요
- CTC가 자동으로 EMG-문자 정렬 학습, 프레임별 라벨링 불필요
-
실시간 처리 가능 Causal masking으로 온라인 디코딩 스트리밍 지연 최소화
Representation Invariance Learning
그럼 이제 학습에 대해 이야기해보겠습니다. 제가 이 논문을 읽게 된 이유도 이 학습에 대한 부분입니다.
기본적으로 EMG 신호들은 가변성이 정말 심합니다. 변동 요인들이 여러 가지 있는데요.
첫째, 사용자마다 근육량, 피하지방, 해부학적 구조가 다릅니다.
둘째, 밴드를 착용할 때마다 전극 위치가 미세하게 다릅니다.
셋째, 팔 각도, 손목 회전 상태 등 자세 변화에 따라 변동됩니다.
넷째, 같은 제스처라 할지라도 EMG 파워 세기가 다릅니다.
이외에도 생물학적인 여러 요인들 때문에 가변성이 심합니다. 논문에서 연구진들은 “같은 제스처끼리의 차이”가 “다른 제스처끼리의 차이”만큼 크다 라고 이야기를 합니다.
그러면 어떻게 학습을 하고 일반화를 해야 할까요? 바로 LSTM의 계층적 불변성을 학습하는 겁니다. 논문에서 진행한 실험을 바탕으로 설명해보도록 하겠습니다.
-
실험 설계
-
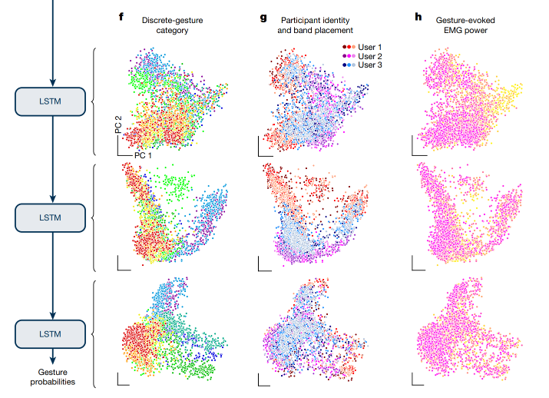
50명 × 3세션 = 150개 녹음 각
-
제스처당 500ms EMG 스니펫 추출
-
LSTM 3개 층의 hidden state 분석
-
-
분석 방법
- 각 LSTM 층에서 표현의 분산이 어떤 요인에 의해 설명되는지 계산
X: LSTM 표현 벡터
ξ: 특정 요인 (제스처/사용자/위치/파워)
분자: 해당 요인별 평균들의
분산 분모: 전체 분산
-
레이어 별 분석
Layer 1 (얕은 층)
-
제스처별 클러스터가 흐릿함
-
같은 제스처도 사용자/세션별로 분산
-
색깔(제스처)보다 모양(사용자)이 더 뚜렷
Layer 3 (깊은 층)
-
제스처별 클러스터가 명확히 분리
-
사용자/세션 영향 최소화
-
같은 제스처는 누가 해도 비슷한 위치
-
LSTM 뿐만 아니라 데이터 다양성을 통한 학습을 통해 가변성 문제를 해결합니다. 4,900명의 다양한 사용자 데이터로 학습하면서, 네트워크는 자연스럽게 공통 패턴을 추출할 수 있게 됩니다. 논문에는 없지만 제가 한번 학습 과정을 간단하게 의사코드로 만들어 봤습니다.
# 의사코드로 표현한 학습 과정
for 배치 in 학습데이터:
사용자1_검지핀치 = [EMG패턴A]
사용자2_검지핀치 = [EMG패턴B] # A와 매우 다름
사용자3_검지핀치 = [EMG패턴C] # 또 다름
# 네트워크는 A,B,C의 공통점을 찾아야 함
# → 표면적 차이를 무시하고 본질적 패턴 학습
LSTM을 어떻게 사용했는지 요약하자면 아래와 같습니다.
-
계층적 추상화 - 각 LSTM 층이 점진적으로 추상화 수준을 높임
-
Layer 1: 원시 EMG 특징 (사용자별 특이성 유지)
-
Layer 2: 중간 수준 패턴 (부분적 추상화)
-
Layer 3: 제스처 개념 (사용자 무관한 추상 표현)
-
-
정보 병목 원리 (Information Bottleneck)
- LSTM의 제한된 hidden state (512차원)가 자연스럽게 불필요한 정보를 버리도록 유도
-
이러한 불변성 학습 결과
-
Cross-user 일반화: 새로운 사용자도 캘리브레이션 없이 사용 가능
-
Session 간 안정성: 밴드를 다시 착용해도 성능 유지
-
자세 강건성: 팔 각도가 바뀌어도 인식 가능
-
결국 이러한 과정의 가장 중요한 이유이자 결과는 “개인별 튜닝 없이 작동하는 범용 EMG 디코더를 실현” 입니다.
여기까지가 논문의 내용입니다. 그러나!! 특별히, 오늘 포스팅에서는 제가 논문을 읽고 어떠한 생각을 거치는지까지도 포스팅을 해볼까 합니다.
저는 연구실에서 메인 프로젝트와 서브 프로젝트를 하나씩 담당하고 있는데요, 그 과정에서 논문을 읽고 끝내는 것이 아니라 내 프로젝트에 어떻게 적용할까??!! 를 항상 생각합니다.
처음에 제가 국가 연구 과제를 하면서 이 논문을 읽었다고 했는데, 현재 이 과제는 절단 환자를 위한 의족을 만드는 과제라고 생각하시면 됩니다. 그러면 이 논문을 통해 제가 프로젝트에 어떻게 적용해보면 좋을지 생각한 과정도 공유하겠습니다.
-
현재 상황 분석 및 핵심 차이점
-
Meta 연구: 6,000명+ 건강한 사람 데이터
-
현재 프로젝트: 제한된 수의 절단 환자 데이터
-
잔존 근육의 EMG 패턴이 환자마다 상이함
-
-
데이터 부족 접근 전략
-
1단계: 건강한 사람의 보행 EMG로 사전학습
-
2단계: 절단 환자 데이터로 fine-tuning
-
Contrastive Learning
-
계층적 LSTM으로 불변성 학습
-
환자별 fine-tuning (논문에서 학습 데이터 규모가 커졌을 때 fine-tuning은 의미 없다 했지만 데이터가 부족한 상황에서는 유의미하다고 언급)
-
-
MPF Features 도입
“MPF features offer clear advantages on the wrist classification task over RMS power” 논문에서 언급
이런 식으로 항상 논문을 프로젝트에 어떻게 적용할까 고민합니다. 😊😊 오늘 포스팅 마무리하겠습니다.
Follow my github
{kind=link}