MelFusion 이란?
by DINHO
오늘은 Chowdhury, Sanjoy, et al. “Melfusion: Synthesizing music from image and language cues using diffusion models.” 논문에서 소개한 MelFusion이라는 모델에 대해 이야기해보겠습니다. 이 논문은 탑 티어 컨퍼런스인 CVPR에서 Highlight, Top 2.8%의 엄청난 논문입니다! 한 번 같이 보겠습니다. Introduction, Method, Experiments and Results, Discussion 순서로 이야기하겠습니다.
(기존 오디오 및 음악 생성형 AI 논문에서 항상 비슷한 이야기를 하고 있어서 Related Work는 생략하겠습니다. 또한, 논문에서는 Method라는 항목이 없고, Synthesizing Music from Image and Text 항목이 있는데, 저는 Method라고 하고 소개드리겠습니다.)
Introduction
Text-to-Music 모델들은 주어진 텍스트 설명을 바탕으로 음악을 생성하지만, 이미지 정보를 활용하지 못하는 한계가 있습니다. 예를 들어 음악가들은 영화 음악을 작곡할 때 단순히 시나리오(텍스트)만이 아니라 영상(이미지)도 참고하여 감정을 효과적으로 표현합니다. 따라서 이미지와 텍스트를 모두 활용할 수 있는 음악 생성 모델 이 필요하다고 이야기하고 있습니다.
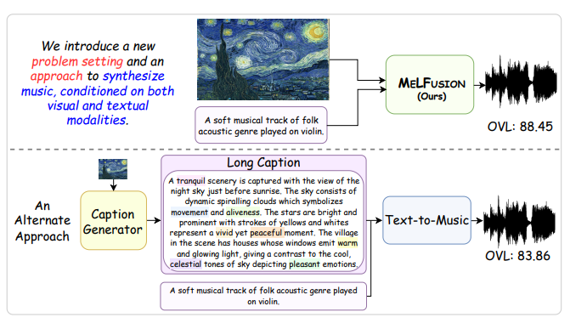
[그림 1] Introduction of Melfusion
현재 음악 생성 모델들은 Text-to-Music 모델이 주류이며, 멜로디나 허밍을 입력 조건으로 활용하는 경우는 있습니다. 하지만 이미지를 활용한 음악 생성 연구는 거의 존재하지 않습니다.
이 과정에서 이미지를 [그림 1] 아래와 같이 활용할 수는 있습니다. 이미지를 텍스트로 변환하는 갭션 생성 모델을 하용하고, 그 캡션을 Text-to-Music에 입력하는 것이죠. 그러나 이러한 접근 방식은 세부적인 이미지 정보를 반영하지 못하고 품질이 떨어집니다. 논문에서는 이 과정이 지루하다(tedious)고 이야기합니다.
따라서 다음과 같이 논문의 기여를 이야기할 수 있습니다.
-
참조 이미지 및 관련 텍스트와 일치하는 음악을 생성하는 새로운 확산 모델 MelFusion 개발
-
11,250개의 ⟨이미지, 텍스트, 음악⟩ 트리플릿으로 구성된 새로운 데이터셋 MeLBench 구축
-
이미지-음악 쌍 간의 대응 관계를 정량적으로 확립하기 위해 새로운 메트릭 IMSM을 제안
-
FAD 점수에서 최대 67.98%의 상대적 이득을 보여줌
-
주관적, 객관적 평가 모두에서 기존보다 성능이 뛰어나다는 것을 보여주며, 이를 통해 Multi-Modal음악 합성을 위한 새로운 벤치마크를 설정
Method
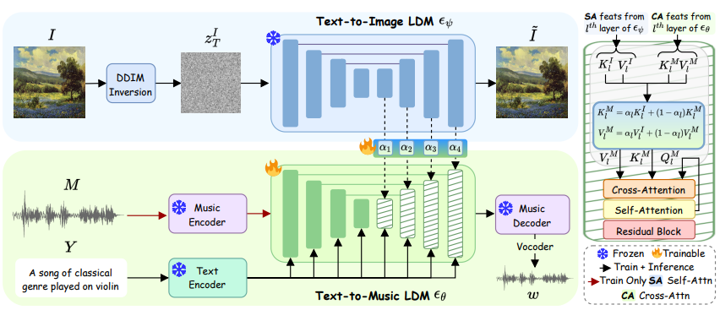
[그림 2] Structure of Melfusion
그림에서 파란 부분과 초록 부분을 나눠서 설명해보겠습니다. 먼저 파란 부분은 이미지에서 시각적 특징을 추출하여 음악 생성에 반영 하는 부분이고 초록 부분은 시각적 특징을 텍스트-음악 생성 모델에 효율적으로 결합 하는 부분입니다. 자세히 부분 별로 천천히 알아보겠습니다.
Text-to-Image LDM
이미지를 처리하는 파란 박스부터 설명해보겠습니다.
-
DDIM Inversion을 통한 이미지 변환
먼저, 입력 이미지 \(I\) 를 DDIM(Denoising Diffusion Implicit Model) 을 통해 잠재 표현 \(z_{T}^{I}\) 로 변환합니다.
이 과정은 확산 모델에서 역방향 샘플링을 위한 과정입니다.
-
Self-Attention Feature Extraction
확산 역과정을 거쳐 Text-to-Image LDM의 디코더에서 Self-Attention 피처를 추출 합니다. 확산 과정의 Self-Attention 연산은 다음과 같이 나타낼 수 있습니다.
\[Q = W^q f, \quad K = W^k f, \quad V = W^v f\] \[\text{Attention}(Q, K, V) = \text{Softmax} \left( \frac{Q K^T}{\sqrt{d_k}} \right) V\]-
\(f\) 는 피처 맵
-
\(W^q, W^k, W^v\) 는 Self-Attention을 위한 가중치 행렬
-
\(d_k\) 는 Attention 차원
-
이 과정에서 추출 된 \(K^I\) , \(V^I\) 값이 이후 음악 생성 과정에서 활용됩니다.
-
Text-to-Music LDM with Visual Synapse
이제 초록 박스를 볼까요? 이 부분은 위에서 추출한 Self-Attention 피처를 Text-to-Music 모델과 융합하여 음악을 생성 하는 과정입니다.
-
Text-to-Music LDM
음악 \(M\) 을 멜-스펙트로그램 \(S\) 로 변환 후, AudioVAE를 통해 잠재 표현 \(Z_{1}^{M}\) 을 얻습니다.
-
Forward Diffusion Process
\(Z_{1}^{M}\) 을 점진적으로 노이즈 \(Z_{T}^{M}\) 로 변환 하는 과정입니다. 노이즈가 추가되는 과정은 Markovian Noise Process 를 사용합니다.
\[q(z_t^M | z_{t-1}^M) = \mathcal{N} \left( z_t^M ; \sqrt{1 - \beta_t} z_{t-1}^M, \beta_t \mathbf{I} \right)\]-
\(\beta_t\) 는 시간 스텝 \(t\) 에서의 분산 스케줄
-
$$q(z_t^M z_{t-1}^M)\(는 __이전 스텝__\)z_{t-1}^M\(__에서__\)z_t^M$$ 으로 변환되는 확률 분포
-
-
Visual Synapse: 이미지-음악 정보 융합
이 부분이 논문의 핵심인데요!! 기존 Text-to-Music 모델과 다르게, 이미지의 Self-Attention 피처를 음악 생성 과정에 결합합니다. 이를 위해 학습 가능한 가중치 \(\alpha_l\) (learned layer specific α parameters) 를 적용하여 다음과 같이 결합합니다.
\[K_l^M = \alpha_l K_l^I + (1 - \alpha_l) K_l^M\] \[V_l^M = \alpha_l V_l^I + (1 - \alpha_l) V_l^M\]-
\(K_l^I\) , \(V_l^I\) 은 파란 박스에서 추출된 Self-Attention 특징 입니다.
-
\(K_l^M\) , \(V_l^M\) 은 초록 박스에서 사용하는 Cross-Attention 특징 입니다.
-
\(\alpha_l\) 은 학습 가능한 가중치로, 이미지의 영향 을 조절하는 역할을 합니다.
-
-
Reverse Diffusion Process: 음악 생성
위 과정을 거친 후, 역확산을 수행하여 음악 잠재표현을 생성합니다. 잠재표현은 VAE Decoder를 거쳐 멜 스펙트로그램으로 변환되고, 멜 스펙트로그램은 Vocoder를 거쳐 원시 오디오 신호로 변환됩니다. 이 때 Vocoder는 HiFiGAN입니다.
Overall Frame Work
논문에서는 전체적인 프레임 워크를 알고리즘으로 잘 적어 두었습니다. 참고하시면 좋을 것 같습니다.

[알고리즘] MeLFusion: Training and Sampling
Experiments and Results
실험에는 새로운 데이터셋 MeLBench 를 제안했습니다. <이미지, 텍스트, 음원> 트리플릿으로 구성되었습니다. 또한, MusicCaps 데이터셋을 확장하여 실험을 진행하였습니다.
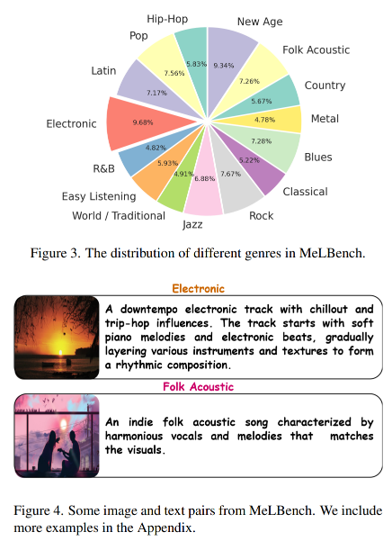
[그림 3] The distribution of different genres in MeLBench
IMSM(Image-Music Similarity Metric)
아까 소개에서 말씀 드렸다시피 IMSM이라는 새로운 평가지표를 제안하였습니다. 수식은 아래와 같습니다.
\[A_{\text{IMSM}} = A_{\text{CLIP}} A_{\text{CLAP}}^T\]수식은 간단합니다. 기존에 이미지와 캡션 사이의 유사도를 나타내는 CLIP와 오디오와 캡션 사이의 유사도를 나타내는 CLAP를 내적하여 계산합니다. 즉 텍스트를 브릿지(Bridge) 삼아 이미지와 오디오 사이의 관계를 나타내는 평가지표로 제안한 것입니다.(이런 간단하면서도 획기적인 아이디어는 대체 어떻게 생각해내는지… 대단할 뿐입니다.)
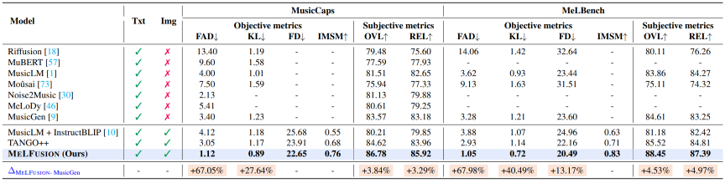
[표 1] Results of Experiments
표를 보면 알 수 있듯이 MeLFusion의 성능이 더 좋다고 논문에서는 이야기하고 있습니다.
Discussion
-
IMSM 점수가 높은 편(0.83)이지만 완벽한 매칭(1.0)에는 도달하지 못함: 이미지의 감성, 분위기, 색감과 사운드의 관계를 더 깊이 반영하는 방법을 개발할 것이라고 이야기하고 있습니다.
-
모델의 계산 비용이 높음: 기본적으로 LDM 두 개를 사용하기 때문에 계산 비용이 굉장히 높습니다. 앞으로 경량화 된 Diffusion을 사용하고, U-Net을 더 효율적으로 설계할 것이라고 이야기하고 있습니다.
-
MeLBench 데이터셋은 MusicCaps를 확장하여 구축했지만, 여전히 데이터셋 크기가 제한적
마무리
이 논문에서는 앞으로 비디오 기반 음악 생성 확장을 계획하는 등의 Future Work도 이야기하고 있습니다. 이 논문을 읽으면서 느끼는 점이 큽니다.
간단한 아이디어임에도 어떻게 이런 생각들을 할 수 있는지 놀랐습니다. (앞으로 있을 대학원 생활에 벽을 느꼈달까요…) 그리고 이렇게 글이 깔끔하고 말하고자 하는 바가 명확하며, 아이디어까지 좋은 논문이 탑티어 컨퍼런스에서도 우수한 평가를 받는다는 것을 느꼈습니다. 저도 이런 논문을 작성할 수 있도록 열심히 공부해야 할 것 같습니다.😂😂 오늘은 여기서 마무리하겠습니다! 감사합니다.
Follow my github
{kind=link}