VAE(Variational autoencoder)란?
by DINHO
오늘은 VAE(Variational autoencoder)에 대해서 이야기해보겠습니다. VAE에 대해 처음으로 소개한 논문은 Kingma와 Welling에 의해 2013년에 작성된 “Auto-Encoding Variational Bayes”입니다. 이 논문에서는 VAE의 기본 원리와 함께, 딥러닝을 이용한 변분 베이지안 추론(Variable Bayesian Inferench)의 새로운 방법을 제시했습니다. 이 논문은 VAE의 이론적 기반을 마련하고, 다양한 분야에서의 응용 가능성을 열어준 중요한 작업으로 평가받고 있습니다.
수식적으로 복잡한 내용이 있기 때문에 간단한 개념 정도만 궁금하신 분들을 위해 전체 내용 정리 이후 자세한 포스팅 진행하겠습니다😁😁
VAE 간단 정리
이 논문에서는 i.i.d. 데이터 세트와 데이터 포인트당 연속 잠재 변수를 고려하여 AEVB(AutoEncoding VB) 알고리즘을 제안합니다. AEVB 알고리즘에서는 SGVB (Stochastic Gradient Variational Bayes) 추정기를 사용하고 간단한 조상 샘플링을 사용하여 매우 효율적인 근사 사후 추론을 수행할 수 있는 인식 모델을 최적화함으로써 추론 및 학습을 특히 효율적으로 만듭니다. 이를 통해 데이터 포인트당 expensive iterative inference schemes(예: MCMC) 없이도 모델 매개변수를 효율적으로 학습할 수 있습니다. 학습된 근사 사후 추론 모델은 인식, 잡음 제거, 표현 및 시각화 목적과 같은 다양한 작업에도 사용될 수 있습니다. 인식 모델에 신경망을 사용하면 VAE에 도달합니다.
-
변분 추론과 딥 러닝의 결합: 논문의 핵심 기여 중 하나는 변분 추론(variational inference)을 딥 러닝과 결합하여, 대규모 데이터셋에서 복잡한 확률 모델을 효율적으로 학습할 수 있는 방법론을 제공하는 것입니다. 이 방법은 특히 생성 모델에서 유용하며, 높은 차원의 데이터에 대한 강력한 모델링 능력을 입증합니다.
-
재구성 오류와 KL 발산 최소화: VAE의 학습 과정에서는 재구성 오류(Reconstruction error)와 KL 발산(Kullback–Leibler divergence)을 최소화하는 것이 중요합니다. 재구성 오류는 생성된 데이터와 실제 데이터 사이의 차이를 측정하며, KL 발산은 잠재 변수의 사후 분포와 사전 분포 사이의 차이를 측정합니다. 이러한 최적화를 통해, 모델은 데이터의 효율적인 잠재 표현을 학습하고, 잠재 공간에서 의미 있는 샘플링을 가능하게 합니다.
-
스토캐스틱 그래디언트 디센트를 통한 학습: VAE 모델은 스토캐스틱 그래디언트 디센트(SGD)와 그 변형을 사용하여 학습됩니다. 이 접근 방식은 대규모 데이터셋에서의 학습을 가능하게 하며, 모델의 확장성과 실용성을 크게 향상시킵니다.
-
다양한 응용 분야: VAE는 이미지 생성, 음성 인식, 텍스트 모델링 등 다양한 분야에서 응용될 수 있습니다. 이 논문은 VAE가 복잡한 데이터 구조를 모델링하고, 새로운 데이터를 생성하는 데 어떻게 사용될 수 있는지를 보여주는 여러 실험을 통해 그 가능성을 시연합니다.
이 논문은 복잡한 데이터 분포를 효과적으로 학습하고 새로운 데이터를 생성할 수 있는 강력한 프레임워크를 제공함으로써, 기계 학습과 인공 지능 분야에 광범위한 영향을 미쳤습니다. VAE의 등장은 이후 GAN와 같은 다른 생성 모델의 발전에도 영감을 주었으며, 지속적으로 연구되고 발전되고 있는 핵심 주제 중 하나입니다.
그렇다면 이제 본격적으로 수식과 함께 논문에서 이야기하는 VAE에 대해서 포스팅하겠습니다.
VAE 파헤치기
-
Method
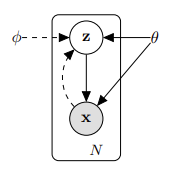
이 논문에서 Auto-Encoding의 Method를 이야기를 하는 section의 전략은 연속 잠재 변수가 있는 다양한 directed graphical 모델에 대한 하한 추정량(stochastic objective function)을 도출하는 데 사용할 수 있습니다. 자세한 설명은 아래와 같습니다.
- 잠재 변수 \(Z\) : Z는 모델의 잠재변수입니다.
- Data \(X\) : X는 모델이 학습하려고 하는 실제 데이터 포인트입니다.
- \(\theta\) : 생성 모델의 파라미터입니다.
- Variational parameters \(φ\) : 변분 추론을 통해 학습되는 파라미터로, \(\theta\) 와 함께 학습됩니다.
모델에서 실선은 생성 모델 \(p_{\theta}(z)p_{\theta}(x\vert z)\) 를 나타내고 점선은 interactable posterior \(p_{\theta}(z\vert x)\) 에 대한 변형 근사 \(q_{ϕ}(z\vert x)\) 를 나타냅니다.
-
Problem scenario
이 부분부터는 어려운 내용이니 요약을 먼저 해보겠습니다. 이 논문에서는 marginal 혹은 posterior probabilities를 직접 계산할 수 없는 복잡한 경우에도 효율적으로 작동할 수 있는 알고리즘을 제안합니다. 이 알고리즘은 특히 큰 데이터셋에 대해 실시간으로 업데이트할 수 있는 효율적인 방법을 제공하며, 잠재 표현을 학흡하여 데이터의 생성 과정을 모방하고, 더 나은 데이터 표현을 위한 사후 추론을 가능하게 합니다.
그럼 논문에서 이야기하는 문제 상황에 대해 자세히 설명해보겠습니다.
먼저 논문에서와 같이 일부 연속 또는 이산 변수 x의 N i.i.d. 샘플로 구성된 데이터 세트 \(X = {x^(i)}^{N}_{i=1}\) 을 고려해 보겠습니다. 이 샘플들은 관찰되지 않은 연속 확률 변수 z를 포함하는 일부 랜덤 프로세스에 의해 생성되었다고 가정합니다. 이 과정은 두 단계로 나뉩니다.
-
첫 번째로 \(z^{(i)}\) 는 사전 분포 \(p_{\theta}*(z)\)에서 생성됩니다.
-
두 번쨰로 \(x^(i)\) 는 일부 조건부 분포 \(p_{θ}*(x\vert z)\) 에서 생성됩니다. (이외의 가정은 생략하겠습니다.)
이 과정의 많은 부분은 우리의 눈에 안 보이고 숨겨져 있어서 진짜 파라미터 \(\theta\) 와 잠재 변수 \(Z^{(i)}\) 의 값은 우리에게 알려지지 않았습니다.
매우 중요한 것은 marginal 확률이나 사후 확률에 대해 일반적인 단순화 가정을 하지 않는다는 것입니다. 반대로 논문에서는 아래와 같은 경우에도 효율적으로 작동하는 일반 알고리즘에 관심을 두었습니다.
-
다루기 힘든 경우 : marginal likelihood의 적분 \(p_{\theta}(X) = \int p_{θ}(z)p_{\theta}(x\vert z)\) 의 적분이 불가능한 경우(즉, marginal likelihood를 평가하거나 구별할 수 없는 경우), 실제 사후 밀도 \(p_{\theta}(z\vert x) = \frac{p_{\theta}(x\vert z)p_{\theta}(z)}{p_{\theta}(x)}\) 를 다루기 불가능 한 경우(즉, EM알고리즘을 사용할 수 없는 경우), 합리적인 평균 필드 VB 알고리즘에 필요한 적분도 불가능한 경우. 이러한 난해성은 비교적 복잡한 likelihood \(p_{\theta}(x\vert z)\) 의 경우에 나타납니다. (e.g. 비선형 은닉층이 있는 신경망)
-
대규모 데이터 세트 : 데이터가 너무 많으면 배치 최적화에 비용이 많이 듭니다. 이 논문에서는 작은 미니 배치나 단일 데이터 포인트를 사용하여 매개변수 업데이트를 만들고자 했습니다. 샘플링 기반 솔루션(e.g. Monte Carlo EM)은 일반적으로 데이터 포인트 당 비용이 많이 드는 샘플링 루프를 포함하기 때문에 속도가 매우 느립니다.
위의 시나리오에서, 논문은 세 가지 관련 문제에 관심이 있으며 이에 대한 해결책을 제안합니다.
(1) 파라미터 \(\theta\) 에 대한 ML(Maximum Likelihood) 또는 MAP(Maximpum A Posterior)의 효율적인 근사 : 예를 들어 자연적인 과정을 분석하는 경우 파라키터 그 자체로 관심이 있을 수 있습니다. 또한, 이를 통해 히든 랜덤 프로세스를 모방하고 실제 데이터와 유사한 인공 데이터를 생성할 수 있습니다.
(2) 파라미터 \(\theta\) 의 선택에 대한 관찰 값 \(x\) 가 주어지면 잠재 변수 \(z\) 의 효율적인 근사 사후 추론 : 이는 코딩이나 데이터 표현 업무에 유용합니다.
(3) 변수 \(x\) 의 효율적인 근사 marginal 추론 : 이를 똥해 x에 대한 사전 확률이 필요한 모든 종류의 추론 작업을 수행할 수 잇습니다. 컴퓨터 비너에서의 흔한 응용 사례로는 이미지 디노이즈, 인페인팅, 초해상도 기술 등이 있습니다.
위에 나온 문제들을 해결하기 위해 논문에서는 인식 모델 \(q_{ϕ}(z\vert x)\) 을 소개합니다. 이는 다루기 힘든 진짜 사후 \(p_{\theta}(z\vert x)\) 에 대한 근사치입니다. mean-field variational inference에서의 근사 사후와 달리, 이는 반드시 factorial되지 않으며, 파라미터 \(ϕ\) 는 닫힌 형식의 기댓값으로부터 계산되지 않습니다. 대신에 논문에서는 인식 모델 파라미터 \(ϕ\) 를 생성 모델 파라미터 \(\theta\) 와 함께 학습하는 방법을 소개하고 있습니다.
코딩 이론 관점에서 \(z\) 는 관찰되지 환는 변수로서 잠재표현으로 해석됩니다. 그러므로 이 논문에서는 인식 모델 \(q_{ϕ}(z\vert x)\) 을 확률적 인코더로 참조합니다. 그 이유는 주어진 데이터 포인트 \(x\) 에 대해, 데이터 포인트 \(x\) 가 생성될 수 있는 코드 \(z\) 의 가능한 값에 대한 분포를 생성하기 때문입니다. 유사한 방법으로 논문에서는 \(p_{\theta}(x\vert z)\) 를 확률적 디코더로 참조하였습니다. 이를 통해 주어진 \(z\) 에 대해 해당하는 가능한 \(x\) 값에 대한 분포를 생성합니다.
-
-
Algorithm

이제 논문에서 이야기하는 AEVB알고리즘에 대해 설명하겠습니다. 이 알고리즘의 응용 버전이 곧 VAE이기 때문에 이 내용은 굉장히 중요합니다.
(1) 파라미터 초기화 : 생성 모델 파라미터 \(\theta\) 와 인식 모델 파라미터 \(ϕ\) 를 초기화합니다.
(2) repeat : 파라미터가 수렴할 때까지 아래의 과정을 반복합니다.
(3) 미니배치 추출 : 전체 데이터셋에서 \(M\) 개의 데이터 포인트를 무작위로 선택하여 미니배치 \(X^{M}\) 을 형성합니다.
(4) 노이즈 샘플링 : 노이즈 분포 \(p(ϵ)\) 에서 랜덤 샘플 \(ϵ\) 를 추출합니다. 이 노이즈는 잠재 공간의 변수를 샘플링 하는 데 사용됩니다.
(5) gradients 계산 : 미니 배치 추정치에 대한 \(\theta\) 와 \(ϕ\) 의 gradient를 계산합니다. \(L^{M}(\theta , ϕ ; X^{M} , ϵ)\) 은 미니배치에 대한 목적함수(variational lower bound)입니다.
(6) 파라미터 업데이트 : 계산된 gradient를 사용하여 파라미터 \(\theta\) 와 \(ϕ\) 를 업데이트합니다.
(7) 수렴 검사 : 파라미터들이 수렴할 때까지 위 단계를 반복합니다. 수렴은 파라미터가 더 이상 크게 변하지 않고, 목적 함수의 값이 최소화 되었거나 안정화 되었음을 의미합니다.
(8) 결과 반환
결과적으로 이러한 알고리즘을 이용해서 VAE를 만들었습니다.
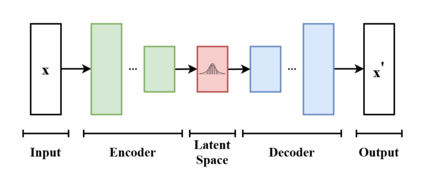 이미지 출처 : wikipedia
이미지 출처 : wikipedia
VAE는 결국 Input X를 Encoder에 통과 시켜 잠재 벡터 z를 구하고, 잠재 벡터 z를 다시 Decoder에 토오가 시켜 기존 input X와 최대한 비슷한 새로운 데이터를 생성하는 모델입니다.
그렇다면 기존에 있는 AE(Auto Encoder)와 VAE는 어떤 차이가 있을까요?
AE vs VAE
-
AE : AE는 Encoder에 초점을 두었습니다. Encoder 학습을 위해 Decoder를 붙인 구로로, input X 자신을 재구성할 수 있는 z를 만드는 것이 목적입니다.
-
VAE : AE와 다르게 VAE는 Decoder에 초점을 두었습니다. 또한 AE의 잠재 코드 값이 이산 값이라면 VAE에서 잠재 코드 값은 가우시안 분포로 표현된다는 차이를 둡니다.
결국 AE는 input을 따라하도록 재구성에 초점을 두고, VAE는 새로운 데이터를 생성하기 위해 Decoder에 초점을 둡니다. 그런데 왜 VAD가 아니라 VAE일까요? 그 이유는 두 모델의 목적은 다르더라도 구조는 비슷하기 때문에 그렇습니다.
내용이 어렵고 방대한 만큼 이번 포스트의 글도 굉장히 기네요. 그럼 다음 포스팅 때 뵙겠습니다.
Follow my github
{kind=link}